Springboot Java - java 21에 도입된 가상스레드란 뭘까?
java 21에 도입된 가상스레드, 기존이랑 어떻게 다른건데?
java 21에서 지원하기 시작한 가상스레드에 대해 알아보자.
가상스레드를 알기 전에 알아야하는 내용
잠깐, 가상스레드 개념을 이해하기 전에 알고 있으면 더 좋을 내용들을 읽어보자.
원래의 Thread는 두 종류다.
가상 스레드에 알아보기 전에 스레드의 종류에 대해 알아보자.
- 커널 레벨 스레드(Kernel-Level Threads)
- 운영체제에서 지원하는 스레드로, 커널이 스레드의 생성이나 스케줄링 등을 관리한다.
- 커널은 프로세스 내의 다른 스레드를 중단시키지 않고, 계속 실행시켜준다.
- 커널은 여러 개의 스레드를 각각 코어에 할당할 수 있다.
- 사용자 스레드에 비해 생성이나 관리하는 것이 느리다.
- 커널은 프로세스 내의 다른 스레드를 중단시키지 않고, 계속 실행시켜준다.
- 사용자 레벨 스레드(User-Level Thread)
- 커널 영역 위에서 동작하며 라이브러리를 통해 구현되고, 이 라이브러리들은 스레드의 생성이나 스레줄링 등에 대한 기능을 제공한다.
- 커널은 프로세스 내부의 스레드를 인식하지 못하기 때문에, 해당 프로세스를 대기 상태로 전환시키면 사용자 레벨의 스레드는 모두 중단된다.
- 같은 메모리 영역에서 스레드가 생성되고 관리되어 빠르다.
- 커널은 프로세스 내부의 스레드를 인식하지 못하기 때문에, 해당 프로세스를 대기 상태로 전환시키면 사용자 레벨의 스레드는 모두 중단된다.
원래 java에서 스레드는 어떻게 동작했을까?
추가된 내용을 알기전에, 원래는 어떻게 동작하고 있었는지 알아보자.
- java 스레드
- I/O, interrupt, sleep과 같은 상황에서 block/waiting 상태가 되고, 이때 운영체제에서는 컨텍스트 스위칭이 발생한다.
- 기존 프로세스를 잘게 쪼개서 프로세스 내의 공통 부분은 유지하면서, 작은 실행단위를 번갈아가 가며 수행되도록 설계되었다. 그래서 프로세스보다는 크기가 작고, 컨텍스트 스위칭 비용도 저렴합니다.
- 요청이 급증하는 서버 환경에서는 많은 스레드의 수를 요구하게 되었고 프로세스보다는 작았지만, mb 단위의 크기를 가지기 때문에 메모리가 제한된 환경에서는 생성할 수 있는 스레드 수가 한정되었습니다.
- 기존 프로세스를 잘게 쪼개서 프로세스 내의 공통 부분은 유지하면서, 작은 실행단위를 번갈아가 가며 수행되도록 설계되었다. 그래서 프로세스보다는 크기가 작고, 컨텍스트 스위칭 비용도 저렴합니다.
기존에는 유저 스레드(java 스레드) N개 생성, 운영체제 스레드 N개 생성해 1:1로 매칭한뒤 사용했다. 조금더 자세히 말하자면,
ExecutorService을 통해 스케줄링 되는java.lang.Thread객체를 실행한다.- 이 실행은 JVM 내에서 JNI를 통해
start()를 호출한다. start()는 커널 스레드를 만들어 실행한다. JVM은 OS에 종속적이기 때문에, OS에 커널에 맞게 커널 스레드를 생성한다.
그러면 결과적으로, 스케줄링은 ExecutorService가 하고 실제 실행은 JNI를 통해 커널에서 실행되는 구조가 된다.
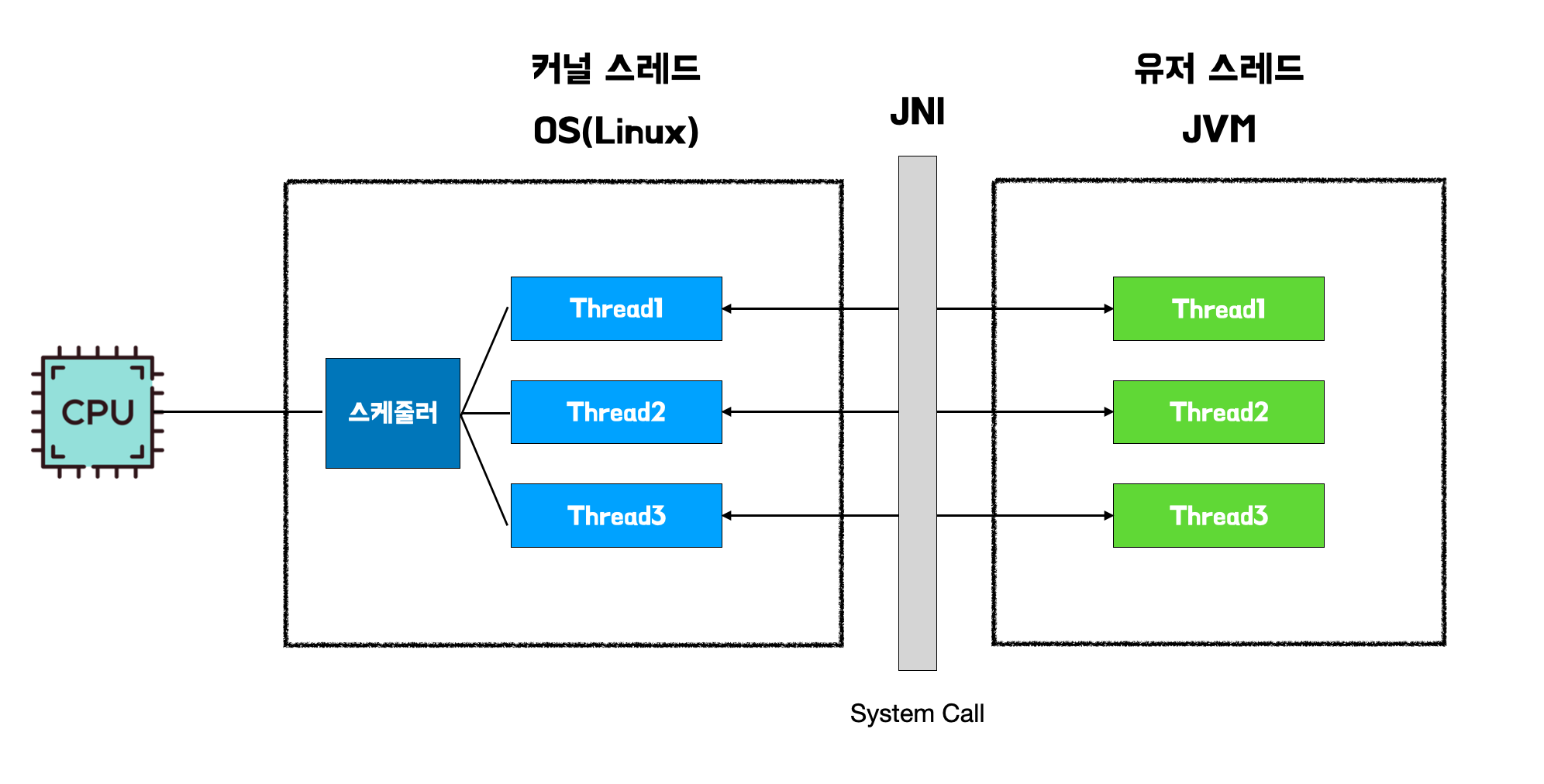 기존 java 스레드가 JNI을 통해 커널에서 실행되는 구조, 출처: 우아한 기술블로그 - Java의 미래, Virtual Thread
기존 java 스레드가 JNI을 통해 커널에서 실행되는 구조, 출처: 우아한 기술블로그 - Java의 미래, Virtual Thread
JNI(Java Native Interface)? Java 애플리케이션에서 네이티브 코드(C, C++ 등)를 호출할 수 있도록 해주는 인터페이스로, 실제 동작은 네이티브 코드에서 한다.
가상스레드?(Virtual Thread)
기존 스레드 모델과 달리 가상스레드는 새로운 구조로 사용된다. 기존에는 커널 레벨 스레드와 유저 레벨 스레드가 1:1로 매핑되어 사용되었는데, 커널 레벨 스레드와 플랫폼 스레드, 가상 스레드가 1:1:N의 구조로 사용된다.
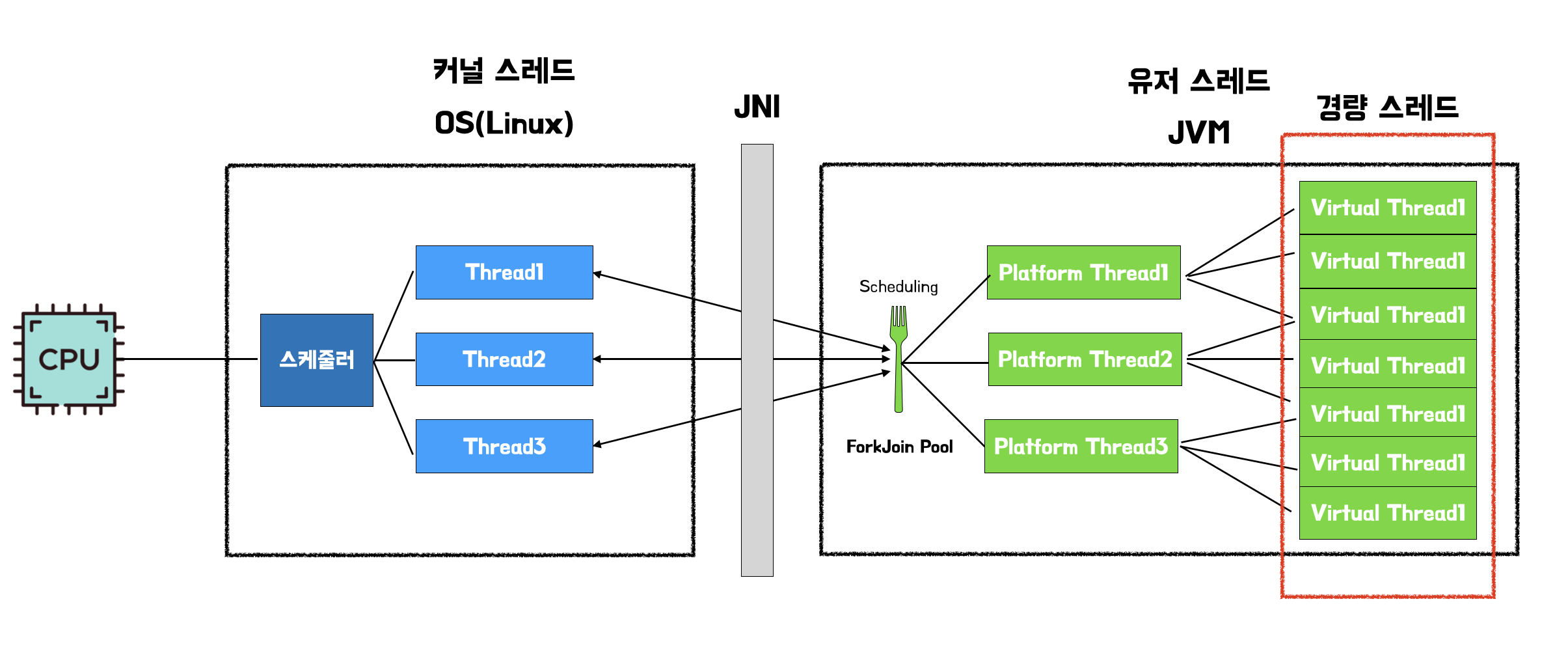 새로운 virtual 스레드가 platform 스레드와 커널 레벨 스레드와 매칭된 구조, 출처: 우아한 기술블로그 - Java의 미래, Virtual Thread
새로운 virtual 스레드가 platform 스레드와 커널 레벨 스레드와 매칭된 구조, 출처: 우아한 기술블로그 - Java의 미래, Virtual Thread
- 플랫폼 스레드(Platform Thread)
- JVM에서 제공하던 스레드로,
java.lang.Thread에 있던 스레드를 의미한다. 사용자 레벨 스레드에는 다양한 언어의 스레드가 해당될 수 있고, java에서 지원하던 스레드를 의미한다.- 운영체제 스레드 위에서 동작하며, 플랫폼 스레드가 종료될 때까지 해당 OS 스레드를 계속 사용한다.
- 커널 레벨 스레드(=운영체제 스레드)와 1:1로 매핑되어 사용된다.
- 운영체제 스레드 위에서 동작하며, 플랫폼 스레드가 종료될 때까지 해당 OS 스레드를 계속 사용한다.
- 가상스레드
- 기존 플랫폼 스레드 대비 가볍고, 대량의 동시성을 처리할 수 있도록 설계된 경량 스레드를 의미한다.
- 가상 스레드는 수명이 짧고, 얕은 호출 스택을 가지고 있다.
가상스레드의 구조
새로운 virtual 스레드가 platform 스레드와 커널 레벨 스레드와 매칭된 구조, 출처: 우아한 기술블로그 - Java의 미래, Virtual Thread
이 그림에서 보면 Fork Join Pool이라는 스케줄러, Platform 스레드, Virtual 스레드 이렇게 3개로 구성되어있는데 이 구조를 좀 더 자세히 보자.
- 커널 레벨 스레드와 플랫폼 스레드, 가상 스레드가 1:1:N의 구조
- 운영체제는 운영체제의 스케줄러를 통해 커널 스레드가 스케줄링 되고, JVM은 Fork Join Pool의 스케줄러를 통해 Platform 스레드가 스케줄링 된다.
- Fork Join Pool에 의해 스케줄링 되는 Platform 스레드는, 여러 개의 Virtual 스레드를 관리하며 실행
- Fork Join Pool
- 작업을 작은 단위로 쪼개서 병렬로 실행하고, 결과를 합치는 방식의 스레드 풀
핵심 구조
- Work Stealing Algorithm: 작업자는 자신의 작업 큐를 가지고 있는데 해당 작업이 끝나면, 다른 작업자의 스레드 큐에서 남은 작업을 가져와 작업
- RecursiveTask: 값을 반환하는 병렬 작업 / RecursiveAction: 값을 반환하지 않는 병렬 작업
동작 방식
- Fork : 작업을 작은 조각으로 쪼갠다.
- 여러개의 worker thread에서 병렬로 실행한다.
- Join : 최종 결과를 합친다.
재귀적으로 분할 가능한 작업(예시: 대량 데이터 처리, 병렬 연산 등)인 경우 적합하게 사용될 수 있다.
가상스레드의 동작 원리
먼저 Fork Join Pool이 가상스레드 구조에서 어떻게 동작하는건지를 정리해보자.
사실은 Fork Join Pool 이 여기서 어떻게 이해되는지 안가서 한참 생각해, 이를 먼저 따로 정리했다.
가상스레드에서 Fork Join Pool
Fork Join Pool은 작업 단위를 쪼개서 병렬로 실행하는 구조인데, 이게 어떻게 가상스레드 구조에서 대응될까?
- Fork Join Pool 동작 방식
- 작업을 쪼갬
- 여러개의 스레드가 쪼개진 작업을 나눠가지고 실행
- 이때 먼저 작업을 끝낸 스레드는 남아있는 작업이나, 다른 스레드가 해야할 작업을 가져와 실행
- 작업 결과를 합침
- 가상 스레드에서 Fork Join Pool의 동작 방식
작업을 쪼갬(삭제)- Platform 스레드가 Virtual 스레드를 실행
- 이때, Virtual 스레드가 block/waiting 되면 다른 Virtual 스레드를 실행
작업 결과를 합침(삭제)
이처럼 작업을 쪼개는 과정과 결과를 합치는 과정은 삭제되고, 쪼개진 작은 작업이 가상 스레드에 대응된다.
가상스레드의 동작 원리
그렇다면 이렇게 ForkJoinPool이 대응되어 동작하는 것을 알고, 자세히 가상스레드의 동작 방식을 보자.
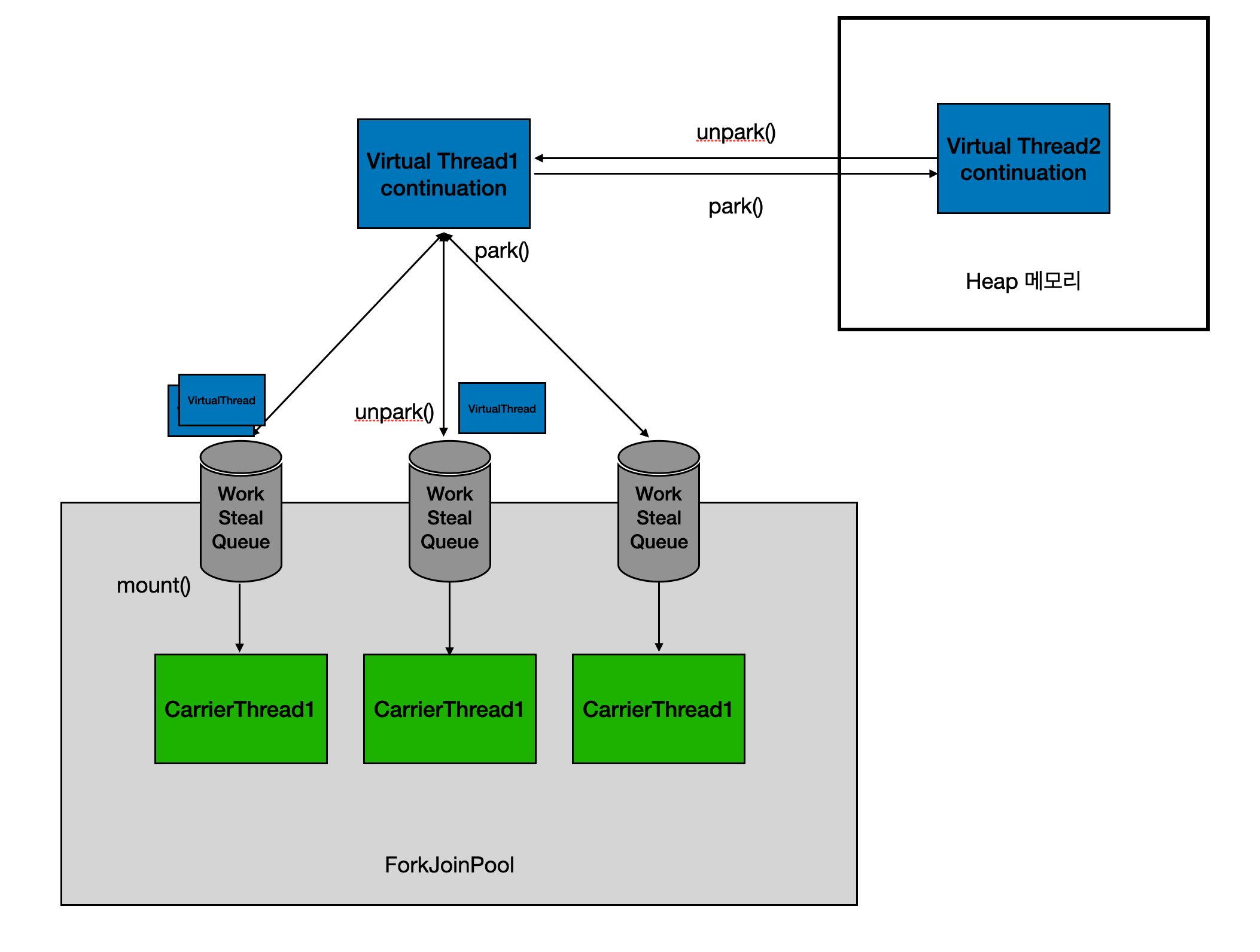 가상스레드의 동작 원리
가상스레드의 동작 원리
- 실행될 continuation(=virtual 스레드의 실행상태)을 carrier 스레드(=platform 스레드)의 work Queue로 push
- carrier 스레드는 가상 스레드의 작업을 work Queue에 보관한다.
- work Queue에 있는 실행될 continuation은 Fork Join Pool에 의해, work Stealing 방식으로 carrier 스레드에 의해 처리
- Fork Join Pool의 스케줄링 방식으로 인해, work stealing 방식으로 carrier 스레드는 work Queue에 있는 작업을 처리한다.
- 처리되던 run continuation들은 block(I/O, interrupt 등)되거나 작업 완료시 work Queue에서 pop 되어 park 과정에 의해 힙 메모리로 이동
- 처리되던 작업내용이 블로킹되거나, 완료된다면 힙 메모리로 이동시킨다.
Platform 스레드와 Carrier 스레드 같은 스레드를 의미하지만, 실제 가상스레드의 동작 원리에서 Platform 스레드가 Virtual 스레드를 감싸서 동작한다는 의미를 강조하기 위한 것이다.
- Continuation
- Virtual Thread의 실행 상태를 저장하는 단위
- 커널 레벨 스레드에서 컨텍스트 스위칭 발생시 실행 중이던 스레드의 레지스터 정보와 실행 상태는 해당 스레드에 관련된 내용을 커널 스택에 저장되는데, 이와 같은 개념으로 가상스레드의 정보와 실행 상태를 말한다.
park()와 unpark() 동작 원리 그림에서 보면, park()와 unpark()가 두 곳에서 호출 되는것처럼 보이는데, 두 곳에서 호출 되는 것이 아니라 하나의 동작을 의미한다.
park()- Virtual 스레드를 Carrier 스레드에서 실행하다가 블로킹 작업이 발생시, virtual Thread의 continuation를 work Queue -> Heap 메모리에 이동
unpark()- Virtual 스레드가 다시 실행될 준비가 되며, virtual Thread의 continuation을 Heap -> work Queue 이동, Carrier 스레드는 이를 Work Queue에서 가져와 실행
즉, 가상스레드 구조에서는 park()와 unpark()를 이용해 컨텍스트 스위칭이 발생하는 형태로 동작한다.
가상스레드의 목표와 장점과 단점
목표
Goals
- Enable server applications written in the simple thread-per-request style to scale with near-optimal hardware utilization.
- 단순한 요청당 스레드(Thread-Per-Request) 방식으로 작성된 서버 애플리케이션이 최적의 하드웨어 활용도로 확장 가능하도록 한다.
- Enable existing code that uses the java.lang.Thread API to adopt virtual threads with minimal change.
- 기존의 java.lang.Thread API를 사용하는 코드가 최소한의 변경만으로 가상 스레드를 사용할 수 있도록 한다.
- Enable easy troubleshooting, debugging, and profiling of virtual threads with existing JDK tools.
- 기존 JDK 도구를 사용하여 가상 스레드의 문제 해결, 디버깅, 프로파일링을 쉽게 할 수 있도록 한다.
출처 : openjdk
이를 통해 본 목표는 기존 Java 스레드 모델을 유지하면서도 확장성과 성능을 극대화하고, 개발자의 코드 변경 부담과 디버깅 부담을 최소화하는 것이다.
장점
이런 가상스레드는 어떤 점이 좋을까?
크게 두가지 장점이 있는데,
- 블로킹 I/O 작업 시 발생하는 컨텍스트 스위칭 비용을 줄인다.
- 기존 스레드 방식에서는 작업 중 블로킹되는 I/O 작업시 운영체제의 컨텍스트 스위칭이 발생했는데, 가상스레드에서 블로킹되는 I/O 작업시 carrier 스레드에서 해제 되므로 운영체제의 컨텍스트 스위칭을 최소화 할 수 있다.
- 운영체제의 컨텍스트 스위칭은 레지스터 정보와 실행상태를 저장하고 불러오는데 오랜 시간이 걸렸지만, 가상스레드에서는 하나의 애플리케이션(=jvm)영역에서 관리되기 때문에 크기도 작고, 빠르다.
- 스레드 생성 비용(메모리, 연산)을 줄인다.
- 커널 레벨 스레드 하나에 가상스레드가 여러개 실행되는 구조기 때문에, 커널 레벨 스레드를 생성하는 비용이 줄어든다.
- 기존에는 JVM 메모리 영역에서 스레드마다 별도의 메모리 영역을 사용했는데, 작동 중인 가상 스레드의 정보는 캐리어 스레드의 영역에 할당하고 작동 중이지 않은(블로킹된) 가상 스레드의 정보는 힙 영역에 할당한다. 그래서 가상스레드만큼의 메모리 영역을 할당받지 않고, 캐리어 스레드만큼의 메모리 할당을 한 뒤 그 메모리를 공유하며 사용합니다.
단점
지금까지 작성한 내용을 보면 가상스레드는 장점만 있는 구조로 느껴질 수 있는데, 그렇지 않다. 정확히는 모든 서비스에 성능 개선을 바라며 적용할 기술은 아니라는 얘기다.
Non-Goals
- It is not a goal to remove the traditional implementation of threads, or to silently migrate existing applications to use virtual threads.
- 기존 스레드 구현을 제거하거나, 기존 애플리케이션을 자동으로 가상 스레드로 마이그레이션하는 것이 목표가 아니다.
- It is not a goal to change the basic concurrency model of Java.
- Java의 기본 동시성 모델을 변경하는 것이 목표가 아니다.
- It is not a goal to offer a new data parallelism construct in either the Java language or the Java libraries. The Stream API remains the preferred way to process large data sets in parallel.
- Java 언어나 Java 라이브러리에 새로운 데이터 병렬성 구조를 제공하는 것이 목표가 아니다. 여전히 대규모 데이터 세트를 병렬로 처리할 때, Stream API를 이용하는 것을 권장한다.
출처 : openjdk
이처럼 가상스레드는 기존 Java의 스레드 모델을 유지하면서도 새로운 확장성을 제공하는 기능이며, 데이터 병렬 처리에는 기존 Stream API를 이용할 것을 권장한다.
왜 데이터 병렬 처리에는 기존 Stream API를 이용할 것을 권장할까? 이유는 가상스레드의 단점과 관련이 있는데, CPU 바운드(CPU-bound) 작업이나 특정 상황에서 오버헤드가 발생할 수 있다는 점이다.
이 부분에 대해 조금 더 자세히 알아보자.
- CPU 바운드 작업의 오버헤드 발생
- CPU 바운드 작업에서는 virtual 스레드의 컨텍스트 스위칭이 발생하지 않습니다. 그럼에도 virtual 스레드를 생성하고 이를 스케줄링하는데, 이에 대한 비용은 발생합니다. 그래서 이러한 부분에 대한 성능 낭비=오버헤드가 발생하기 때문에, platform 스레드를 사용하는 것이 낫습니다.
- 특정 상황의 오버헤드 발생
- Virtual Thread는 수시로 생성되고 소멸되며 스위칭되는데, thread local 변수가 많다면 생성시에는 더 큰 메모리를 사용하게 되고 이동시에는 thread local 변수를 복사해 저장하기 때문에 비용이 증가합니다. 그래서 thread local 변수가 너무 많다면 오버헤드가 발생할 수 있습니다.
- 매우 많은 스레드를 실행할 수 있기 때문에 동기화가 필요한 코드에서 Lock 경합이 증가할 가능성이 높아, synchronized 블록이 많은 코드에서는 Virtual Thread가 오히려 성능을 저하시킬 수 있다.
- 네이티브 메서드를 호출하면 JVM이 직접 제어(코드의 실행 상태를 추적할 수 없기 때문에)할 수 없어, 해당 virtual 스레드가 carrier 스레드를 점유하는 상태가 된다. 이렇게 네이티브 메서드를 호출해 해당 virtual 스레드가 carrier 스레드를 점유하여
park()를 호출해도 되는지 판단할 수 없는 상태를 Pinning, Pinned 라고 한다. - 매우 많은 스레드를 실행할 수 있기 때문에 동기화가 필요한 코드에서 Lock 경합이 증가할 가능성이 높아, synchronized 블록이 많은 코드에서는 Virtual Thread가 오히려 성능을 저하시킬 수 있다.
그 외에 주의점으로는 No Pooling이 있다. Pooling은 스레드 풀이라고 이해하면 되는데, 미리 일정 개수의 스레드를 생성해놓고 재사용하는 것을 의미한다. 기존 스레드는 생성과 소멸 비용이 크기 때문에 Pooling 이 효과적이였지만, 가상스레드는 생성비용이 작기 때문에 미리 가상스레드를 생성해놓는 행위 자체가 오히려 성능 낭비가 될 수 있다. 그래서 필요할 때마다 생성하고 GC에 의해 소멸되도록 방치하는 것이 좋다.
정리하자면, 가상스레드는 CPU 바운드가 아닌 대량의 I/O 바운드의 작업을 하는, 요청당 스레드(Thread-Per-Request) 모델을 사용하는 서버에 적합하다.
thread pool을 사용하면 되는거 아닌가?
가상스레드의 개념을 얕게 이해했을 때에는 기존의 thread pool에서, 미리 생성할 thread의 수를 잘 조절하는 것과 뭐가 다를까? 라는 생각을 헀다. 내가 가상스레드의 컨텍스트 스위칭 비용의 크기와 커널 레벨의 스레드의 컨텍스트 스위치 비용이 어떻게 다른지 몰랐기 때문이라고 생각한다. 이 글을 작성하며, 가상스레드의 동작원리와 그래서 발생되는 컨텍스트 스위칭 비용의 차이를 알게되니 잘못생각했다는 것이 명확해졌다.
또, 처음 개념을 이해했을때에는 무조건 사용해야하는, 어디든 적용하면 성능이 개선되는 새로운 기술이 나왔다고 생각했는데 아니라는 점도 명확하게 알게 되어 좋았다.
그리고 가상 스레드를 공부하며 Java의 가상 스레드와 비슷한 개념들이 이미 존재했고, Kotlin의 코루틴(Coroutines)과 Go의 고루틴(Goroutines)도 유사한 방식으로 동작한다는 것을 알게 되었다.