카프카 핵심 가이드 - 03 카프카에 메세지 쓰기
카프카 프로듀서를 사용하는 방법을 배워보자. KafkaProducer와 ProducerRecord 객체를 어떻게 생성하는지, 어떻게 카프카에 레코드를 전송하는지, 그에 따른 리턴이나 에러를 어떻게 처리하는지와 설정 옵션, 시리얼라이저 등을 살펴보자.
프로듀서 개요
서로 다른 요구 조건은 카프카에 메시지를 쓰기 위해 퓨로듀서 API를 사용하는 방식과 설정에 영향을 미친다.
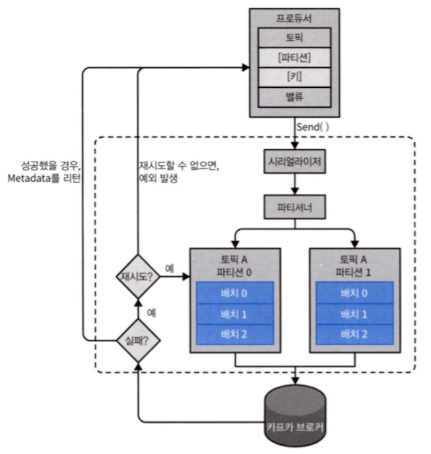 카프카에 데이터를 전송할 때 수행되는 주요 단계들
카프카에 데이터를 전송할 때 수행되는 주요 단계들
ProducerRecord객체를 생성한다.- 레코드가 저장될 토픽과 밸류 지정을 필수사항이다.
- 키와 파티션 지정은 선택사항이다.
- 생성한 객체를 직렬화한다.
- 해당 데이터를 파티셔너에게 보낸다.
- 파티션을 명시적으로 지정했다면 이 과정은 생략된다.
- 파티셔너는 파티션을 결정하는 역할을 한다.
- 토픽 파티션에 저장될 레코드들을 모아 레코드 배치에 추가한다.
- 별도의 스레드가 이 레코드 배치를 적절한 카프카 브로커에게 전송한다.
- 브로커가 메시지를 받으면 응답을 돌려준다.
- 성공했을 경우에는
RecordMetadata를, 실패했을 때는 에러가 리턴된다.
카프카 프로듀서 생성하기
카프카에 메시지를 쓰려면 원하는 속성을 지정해서 프로듀서 객체를 생성해야한다. 이때 프로듀서는 아래의 3개의 필수 속성값을 갖는다.
필수 속성값
bootstrap.servers- 프로듀서가 사용할 브로커의
host:port목록이다.- 모든 브로커를 포함할 필요는 없지만, 최소 2개 이상을 지정할 것을 권장한다.
key.serializer- 키 값을 직렬화하기 위해 사용하는 시리얼라이저 클래스 이름이다.
org.apache.kafka.common.serialization.Serializer인터페이스를 구현하는 클래스의 이름이 지정되어야한다.VoidSerializer를 사용해 키 타입으로void를 설정할 수 있다. value.serializer- 밸류 값을 직렬화하기 위해 사용하는 시리얼라이저 클래스 이름이다.
프로듀서의 생성 방법
1
2
3
4
5
6
Properties kafkaProperties = new Properties();
kafkaProperties.put("bootstrap.servers", "broker1:9002,broker2:9002");
kafkaProperties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
kafkaProperties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProcuder<String, String> producer = new KafkaProducer<String,String>(kafkaProperties);
프로듀서의 생성방법
- 1
Properties생성 - 3~4메시지의 키값과 밸류값으로 문자열을 사용할 것이므로, 기본제공되는 시리얼라이저를 사용
- 6
Properties를 넘겨줌으로써 새로운 프로듀서 생성
메시지 전송 방법
- 파이어 앤 포켓
- 메시지를 서버에 전송만 하고 끝내는 방식으로, 성공 혹은 실패 여부에 관심을 두지 않는다.
- 프로듀서는 재시도할 수 있는 실패에서는 재전송 실패를 하지만, 재시도를 할 수 없는 에러 발생시에는 재시도 하지 않고 실패에 대한 처리가 없어 메시지가 유실되며 프로듀서는 알 수 없다.
- 동기적 전송
- 메시지를 전송하고 다음 메시지를 전송하기 전까지
get()을 호출해 작업이 완료될까지 기다려 성공 여부를 확인한다. - 비동지적 전송
- 카프카는 언제나 비동기적으로 작동한다.
- 응답을 받는 시점에서 자동으로 콜백 함수가 호출된다.
카프카로 메시지 전달하기
1
2
3
4
5
6
ProducerRecord<String,String> record =new ProducerRecord("CustomerCountry", "Precision Products", "France");
try{
producer.send(redord);
}catch(Exception e){
e.printStackTrace();
}
메시지 전송
- 1
ProducerRecord생성 - 3
ProducerRecord를 전송하기 위해 프로듀서 객체의send()사용 - 메시지는 버퍼에 저장 -> 별도에 스레드가 브로커로 보냄 ->
RecoredMetadata를 포함한Future객체를 리턴 -> 이 코드에서는 값을 무시함
- 3
- 6프로듀서가 카프카로 메시지를 보내기 전에 에러가 발생할 경우, catch절이 실행
- ex) 직렬화 실패(SerializationException), 버퍼가 가득참(TimeoutException), 전송 작업을 수행하는 스레드에 인터럽트 발생시(InterruptException)등
동기적으로 메시지 전송하기
동기적으로 메시지를 전송할 경우, 전송을 요청하는 스레드는 이 시간동안 아무것도 안하면서 기다려야해서 성능이 크게 낮아지기 때문에 잘 사용되지는 않는다.
1
2
3
4
5
6
ProducerRecord<String,String> record =new ProducerRecord("CustomerCountry", "Precision Products", "France");
try{
producer.send(redord).get();
}catch(Exception e){
e.printStackTrace();
}
동기적으로 메시지 전송
- 3 카프카로부터 응답이 올 때까지
Future.get()을 사용해 대기 - 성공적으로 전송되지 않았으면 예외를 발생시키고, 성공했다면
RecordMetadata객체를 받는데 여기에서 메시지가 쓰여진 오프셋 등의 메타데이터를 가져올 수 있다.
- 3 카프카로부터 응답이 올 때까지
- 5 재시도할 수 있는 실패라면 재시도 횟수를 넘었을 경우 실행되고, 재시도할 수 없는 실패라면 바로 실행된다.
- 재시도할 수 있는 실패와 재시도할 수 없는 실패
- 재시도할 수 있는 실패
- 메시지를 다시 전송함으로써 해결될 수 있는 에러를 의미한다.
- 연결 에러 - 연결이 회복되면 해결될 수 있다.
- 재시도할 수 없는 실패
- 메시지 크기가 너무 큰 경우와 같이 재시도를 한다고 해서 해결되지 않는 에러를 의미한다.
재시도할 수 있는 실패에서는 카프카가 자동으로 재시도하도록
KafkaProducer를 설정할 수 있어, 이 경우 재전송 횟수를 다 소진하면 예외를 발생시킨다.
비동기적으로 메시지 전송하기
메시지를 비동기적으로 전송한다면, 많은 메시지를 보낸다고 하더라도 시간은 굉장히 짧게 소요될 것이다. 전송시 응답으로 메타데이터를 주는데 메시지가 완전히 실패한 경우가 아니라면, 이 메타 데이터가 필요한 경우는 대부분 없다. 비동기적으로 전송할 때 에러도 같이 처리하기 위해, 레코드 전송시 콜백을 지정할 수 있도록 한다.
1
2
3
4
5
6
7
8
9
10
11
private class DemoProducerCallback implements Callback {
@Override
public void onCompletion(RecordedMethod recordedMethod, Exception e) {
if(e != null) {
e.printStackTrace();
}
}
}
ProducerRecord<String,String> record =new ProducerRecord("CustomerCountry", "Precision Products", "France");
producer.send(record, new DemoProducerCallback);
비동기적으로 메시지 전송
- 1~8 콜백함수 작성
org.apache.kafka.clients.producer.Callback인터페이스를 구현하는 클래스
- 3~7 콜백함수 작성
- 만약 카프카가 에러를 리턴한다면,
onCompletion()메서드가null이 아닌Exception객체를 받게 된다.
- 11 콜백함수 지정
프로듀서 설정하기
프로듀서는 굉장히 많은 설정값을 가지고 있지만, 모두를 설정할 필요는 없다. 몇몇 설정값은 메모리 사용량이나 성능, 효율, 신뢰성에 영향을 미치는데, 이부분에 대해 알아보자.
클라이언트 아이디
client.id- 브로커가 프로듀서를 구분하기 위해 사용되는 값이다.
- 임의의 문자열을 사용할 수 있다.
쓰기 작업 성공 기준
acks- 작업이 성공했다고 판별하기 위해, 얼마나 많은 파티션 레플리카가 해당 레코드를 받아야 하는지 결정하는 설정값이다.
acks=0- 성공적으로 전달되었다고 간주하고 브로커의 응답을 기다리지 않는다.
- 에러가 발생해 브로커가 메시지를 못받은 경우 메세지는 그대로 유실된다.
- 대신 매우 빠르게 메시지를 보낼수 있어, 높은 처리량이 필요할 때 사용될 수 있다.
- 에러가 발생해 브로커가 메시지를 못받은 경우 메세지는 그대로 유실된다.
acks=1- 리더 레플리카가 메시지를 받는 순간, 성공했다는 응답을 받는다.
- 리터에 크래시가 난 상태에서 해당 메시지가 복제가 안 된 채로 새 리더 선출시, 메시지가 유실될 수 있다.
acks=all- 모든 인-싱크 레플리가에 전달된 뒤에, 성공했다는 응답을 받는다.
- 메시지가 유실되지 않는 방법으로 가장 안전한 형태이지만, 지연 시간은 더 길어진다.
메시지 전달 시간
카프카 2.1부터 ProducerRecord를 보낼 때 걸리는 시간을 두 구간으로 나누어 따로 처리할 수 있도록 했다.
send()호출 ~send()결과 리턴: 이 시간은send()를 호출한 스레드는 블록된다.send()결과 리턴 ~ 콜백 호출: 전송이 실제 완료되기까지 걸린 시간(=ProducerRecord가 전송을 위해 배치에 추가된 시점 ~ (성공, 실패, 재시도 시간 소진)의 시간)과 동일하다.
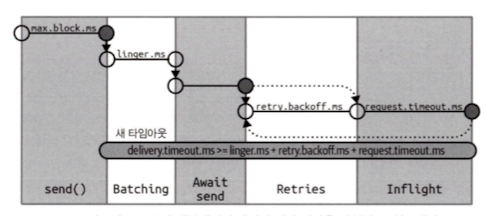 카프카 프로듀서 내부에서 전달 시간을 작업별로 나눈 개념도
카프카 프로듀서 내부에서 전달 시간을 작업별로 나눈 개념도
프로듀서 내부에서의 데이터의 흐름과 서로 다은 설정 매개변수들이 어떻게 상호작용하는지를 보여준다. send() 호출 -> 배치(Batching) -> 전송 대기(Await send) -> 재시도(Retries): 생략 가능 -> Inflight(전송 중)
max.block.mssend()호출 시paritionsFor를 호출해 명시적으로 메타데이터를 요청했을 때,send()리턴의 제한시간을 설정한다.send()는 프로듀서의 전송 버퍼가 가득 차거나 메타데이터가 아직 사용할 수 없을 때 블록된다.
paritionsFor- 프로듀서에서 특정 토픽의 파티션 정보를 조회하는 메서드로, 토픽에 어떤 파티션들이 있는지를 미리 가져올 수 있다.
- 프로듀서는 메타데이터(파티션 정보)를 캐싱하지만,
send()호출 시 필요하면 새로 요청하는데 이때 사용된다.
delivery.timeout.ms- 레코드 전송 준비가 완료된 시점(=레코드가 배치에 저장된 시점)~브로커의 응답을 받거나 전송을 포기하게 되는 시점의 제한시간을 결정한다.
- 이 값은
linger.ms와request.timeout.ms보다 커야한다. - 이 값은
재전송을 횟수가 아닌 시간으로 설정하는 방법 메시지 전송에 기다릴 수 있는 시간을
delivery.timeout.ms로 설정하고,retries를 기본값으로 두는 것(사실상 무한으로 두는 것)이다. 이렇게 설정하면 성공하거나 재시도할 시간이 다 고갈될 때 까지 재전송을 반복한다.
request.timeout.ms- 데이터를 전송할 때 서버로부터 응답을 받기 위해 얼마나 기다릴 것인지를 설정한다.
- 재시도 시간, 실제 전송 이전에 소요되는 시간 등은 포함하지 않는다.
- 메시지를 기준으로 최종적으로 결과가 나오는 전제시간이 아닌, 최초전송 이나 재전송 각 케이스의 응답시간을 의미한다.
- 여기서 타임아웃 발생시
TimeoutException과 함께 콜백을 호출한다. - 재시도 시간, 실제 전송 이전에 소요되는 시간 등은 포함하지 않는다.
retries- 재시도할 수 있는 실패일때 메시지 전송을 포기하고 에러를 발생시킬 때까지, 메시지를 재전송하는 횟수를 설정한다.
retry.backoff.ms- 재시도할 수 있는 실패일때 재전송시, 재전송 사이의 간격을 설정한다.
- 현재 버전에서는 이 값을 조정하는 방법보단, 크래시난 브로커가 정상으로 돌아오기까지의 시간을 테스트한 뒤
delivery.backoff.ms를 설정하는 것을 권장한다. - 현재 버전에서는 이 값을 조정하는 방법보단, 크래시난 브로커가 정상으로 돌아오기까지의 시간을 테스트한 뒤
배치
linger.ms- 적절한 크기의 배치를 만들기 위해 약간의 지연을 주는 역할로 현재 배치를 전송하기 전까지 대기하는 시간을 결정한다.
- 현재 배치가 가득 차거나 or 이 값에 설정된 시간이 되었을 때 배치를 전송한다.
batch.size- 같은 파티션에 다수의 레코드가 전송될 경우 배치 단위로 모아서 한번에 전송하는데, 각 배치에 사용될 메모리의 양(바이트 단위로)을 결정한다.
- 각 배치가 가득 찰 때까지 기다린다는 의미는 아니기 떄문에 큰 값을 유지 한다고 해서 메시지 전송에 지연이 발생되지 않는다.
buffer.memory- 메시지를 전송하기 전에 메시지를 대기시키는 버퍼의 크기를 설정한다.
- send()는 max.block.ms 동안 블록되어 버퍼 메모리에 공간이 생기기를 기다리게 되는데, 확보되지 않으면 예외를 발생시킨다.
배치와 버퍼 메모리의 관계 배치가 곧 버퍼 메모리의 일부로 버퍼 메모리는 메시지가 전송되기 전에 머무르는 공간이고, 이 공간에서 일정 크기인
batch.size로 메시지가 묶여 배치를 형성한 후 전송되는 것이다. 프로듀서는 배치를 파티션 별로 관리하기 때문에, 배치는 파티션 개수만큼 생성될 수 있어, 버퍼 메모리는 여러 개의 배치를 수용할 수 있어야 하므로 파티션 개수와 트래픽을 고려해 충분히 크게 설정 되어야한다.
데이터의 전송시
compression.type- 기본적으로 메시지는 압축되지 않은 상태로 전송되는데,
snappy,gzip,lz4,zstd중 하나로 지정시 해당 알고리즘으로 압축되어 전송된다.
snappy: CPU 부하 적음, 압축률 괜찮음 -> 압축 성능과 네트워크 대역폭 둘 다 중요할 때gzip: CPU 부하 약간, 압축률 더 좋음 -> 네트워크 대역폭이 중요할 때
max.in.flight.request.per.connection- 프로듀서가 응답을 받지 못한 상태에서 전송할 수 있는 최대 메시지의 수를 설정한다.
- 1 이상으로 설정시에는 순서가 뒤바뀔 수 있는데
enable.idempotence값을 설정해 순서가 바뀌지 않도록 할 수 있다. - 1 이상으로 설정시에는 순서가 뒤바뀔 수 있는데
순서가 바뀌는 예시
- 메시지 1번 보냄
- 메시지 2번 보냄
- 매시지 1번 처리 중 장애 발생, 재전송 대기
- 메시지 2번 처리완료
- 메시지 1번 재전송
- 메시지 1번 처리완료
max.request.size- 프로듀서가 전송하는 쓰기 요청의 크기를 결정한다.
- 메시지의 최대크기와 한 번에 요청에 보낼 수 있는 메시지의 최대 개수 역시 제한한다.
- 브로커가 받아들일 수 있는 최대 메시지 크기를 결정하는
message.max.bytes를 동일하게 맞춰야한다. - 메시지의 최대크기와 한 번에 요청에 보낼 수 있는 메시지의 최대 개수 역시 제한한다.
receive.buffer.bytes,send.buffer.bytes- 데이터를 읽거나 쓸 때 소켓이 사용하는 TCP 송수신 버퍼의 크기를 결정한다.
- -1로 설정시 운영체제의 기본값이 사용된다
정확히 한번
0.11부터 카프카는 “정확히 한 번(exactly once semantics)”를 지원하기 시작했다. 멱등적 프로듀서는 간단하면서도 가장 강력한 부분이라고 할 수 있다.
멱등적 프로듀서 일한 메시지를 여러 번 전송해도 최종적으로 브로커에 단 한 번만 기록되도록 보장하는 Kafka 프로듀서의 기능이다.
enable.idempotence=true옵션을 설정하면 멱등적 프로듀서 기능이 활성화된다.
- 신뢰성을 최대하는 방향으로 프로듀서 설정(
acks=all,delivery.timeout.ms는 큰 값으로 설정)하면 메시지는 최소 한번은 카프카에 쓰여지게 된다. - 이러한 상황에서 브로커(=리더)가 프로듀서로 부터 메시지를 받아 로컬 디스크에 쓰고, 다른 브로커(=팔로워)에도 성공적으로 복제되었다고 가정한다.
- 브로커는 프로듀서에게 응답을 보내기 전에 크래시가 발생했다면, 프로듀서는 응답을 받지못해
request.timeout.ms만큼 기다렸다가 재선송을 시도한다. - 이때 브로커는 리더를 새로 선출하는데 최근 데이터를 저장했던 브로커(=팔로워)가 리더로 승격해 리더를 선출했다면, 2에서 팔로워였던 브로커라 이미 데이터가 저장되어 있다. 그런 상태에서 한번 더 데이터를 받게 되면 데이터가 중복으로 저장되게 된다.
enable.idempotence- true로 설정시 프로듀서는 레코드를 보낼 떄 마다 순차적인 번호를 붙여서 보내게되고, 브로커가 같은 프로듀서로부터 동일한 번호의 레코드를 2개 이상 받은 경우에는 하나만 저장하게 되며 문제를 발생시키지 않는
DuplicateSequenceException을 받게 된다.- 만약, 정상적인 순서대로 전송되지 않으면(=seq가 순차적이지 않으면)
OutOfOrderSequenceException을 발생시킨다. - 만약, 정상적인 순서대로 전송되지 않으면(=seq가 순차적이지 않으면)
enable.idempotence=true를 설정하면,max.in.flight.requests.per.connection=5로 자동 조정된다. 멱등적 프로듀서를 사용할 때는 중복 방지뿐만 아니라 순서도 지키는 것이 중요한데,max.in.flight.requests.per.connection값이 너무 크면 네트워크 장애 등으로 인해 일부 메시지가 지연될 경우 나중에 보낸 메시지가 먼저 도착하여 순서가 뒤바뀔 위험도 있다. 그래서 멱등적 프로듀서를 사용시max.in.flight.requests.per.connection값을 5로 조절해 한번에 너무 많이 보내 순서가 바뀔 위험을 줄이는 것이다.만약 아예 순서까지 동일하게 보장이 되어야한다면,
transactional.id을 지정해 트랜잭션을 만든다면 중복과 순서를 모두 정확하게 보장해준다.
정리
- 메시지 생성
- send()메시지 전송
- [생략가능] 토픽의 파티션 정보가 없다면
partitionsFor()호출 send()호출
- [생략가능] 토픽의 파티션 정보가 없다면
- Batching메시지를 배치에 저장
- 메모리(
buffer.memory) 내의 파티션별 배치(batch) 에 저장 - 각 배치는 지정된 시간(
linger.ms) 있다면 해당 값 만큼 기다리며 배치에 저장 - [생략가능] 메시지 압축(
compression.type)이 설정된 경우, 배치 데이터를 압축
- 메모리(
- Await send메시지 전송
- 지정된 배치 사이즈(
batch.size)가 꽉 차면 전송하거나, 가득 차지 않아도 지정된 시간(linger.ms)이 지나면 전송 - TCP 소켓을 통해 브로커로 메시지를 최대 요청 개수(
max.in.flight.requests.per.connection)만큼 전송 - 브로커 응답을
acks설정에 따라 브로커의 응답을 기다림
- 지정된 배치 사이즈(
- Retries전송 실패 시 재시도
- 지정된 응답 시간(
request.timeout.ms)이 지나면 응답을 받지 못했다고 판단해, 지정된 대기 시간(retry.backoff.ms)만큼 대기 후 다시 전송 - 지정된 재전송 횟수(
retries)만큼 반복 - [생략가능]
enable.idempotence=true설정 시,멱등적 프로듀서 중복 체크
- 지정된 응답 시간(
- Inflight최종 전송 완료 or 실패
- 성공시, 메시지 정상적으로 전달되고 콜백 호출
- 실패시 (
delivery.timeout.ms)가 지나면 최종적으로 전송을 포기하며,TimeoutException발생
시리얼라이저
- 시리얼라이저
- 데이터를 직렬화, 역직렬화 시키는 도구이다.
- 프로듀서를 설정할 때는 반드시 시리얼라이저를 지정해주어야 한다.
카프카에서 일반적인 레코드를 직렬화 하는 방법으로 크게 커스텀 시리얼 라이저를 작성해 사용하는 방법과 범용 직렬화 라이브러리 사용하는 방법이 있다.
커스텀 시리얼라이저
범용 직렬화 라이브러리 사용을 강력하게 권장하지만, 왜 그것이 좋은지 알기 위해서 커스텀 시리얼라이저를 작성하는 방법에 대해 알아보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
// 데이터
public class Customer {
private int customerId;
private String customerName;
pulbic Customer(int id, String name) {
this.customerId = id;
this.customerName = name;
}
public int getId() {
return this.customerId;
}
public String getCustomerName() {
return this.customerName;
}
}
// 커스텀 시리얼라이저
import org.apache.kafka.common.errors.SerializationException;
import java.nio.ByteBuffer;
import java.nio.charset.StandardCharsets;
import java.util.Map;
public class CustomerSerializer implements Serializer<Customer> {
@Override
public void configure(Map configs, boolean isKey) {
// nothing to configure
}
@Override
public byte[] serialize(String topic, Customer data) {
try {
byte[] serializedName;
int stringSize;
if (data == null) {
return null;
} else {
if (data.getCustomerName() != null) {
serializedName = data.getCustomerName().getBytes(StandardCharsets.UTF_8);
stringSize = serializedName.length;
} else {
serializedName = new byte[0];
stringSize = 0;
}
}
ByteBuffer buffer = ByteBuffer.allocate(4 + 4 + stringSize);
buffer.putInt(data.getId());
buffer.putInt(stringSize);
buffer.put(serializedName);
return buffer.array();
} catch (Exception e) {
throw new SerializationException("Error when serializing Customer to byte[]" + e);
}
}
@Override
public void close() {
// nothing to close
}
}
데이터와 데이터에 맞는 커스텀 시리얼라이저
이렇게 정의한 시리얼라이저를 사용하게 되면, Customer객체를 전달할 수 있다. 그렇지만 나중에는 문제가 발생할 수 있는데,
Customer객체에 필드가 추가하거나 변경된다면, 기존 데이터와 새로운 데이터의 호환성을 유지해야 한다.- 여러 곳에서 사용하고 있었다면, 사용중인 모든 곳에서 시리얼라이저 내용을 변경해주어야한다.
아파치 에이브로
범용 직렬화 라이브러리로는 에이브로 외에도 스리프트, 프로토버프 등도 있지만, 여기서는 아파치 에이브로에 대해 알아볼 것이다.
- 아파치 에이브로
- 언어 중립적인 데이터 직렬화 형식이다.
- 범용적인 데이터 파일 공유 방식을 제공하는 것을 목표로 더그 컷팅에 의해 시작되었다.
- 언어에 독립적인 스키마의 형태로 기술되며, 파일 자체에 스키마를 내장하는 방법을 쓴다.
- 범용적인 데이터 파일 공유 방식을 제공하는 것을 목표로 더그 컷팅에 의해 시작되었다.
- 더그 컷팅
- 아파치 하둡(Apache Hadoop)과 아파치 루씬(Apache Lucene)의 창시자로 잘 알려진 소프트웨어 엔지니어이다.
호환성 유지하기
메시지를 보내는 애플리케이션이 데이터 형식을 바꿔도, 기존 형식과 호환되기만 하면(=변경점만 변경되고, 기존 부분은 유지된다면) 데이터를 받는 애플리케이션은 아무런 수정 없이 그대로 메시지를 처리할 수 있다는 특징이 있다.
예시로 이해하기
1
2
3
4
5
{
"name": "Alice",
"age": "25",
"fax-number": "1234"
}
1
2
3
4
5
{
"name": "Alice",
"age": "25",
"email": "alice@example.com"
}
데이터의 형식이 왼쪽에서 오른쪽으로 바뀌었다고 가정하면, 변경점인 fax-number와 email만 변경되고 나머지는 기존 형식과 호환된다.
- 데이터를 사용하는 애플리케이션에서 새로운 스키마에 대한 데이터를 받았다면,
fax-number조회시null을 리턴한다. - 애플리케이션을 업그레이드 했을 때, 과거 스키마에 대한 데이터서
email조회시null을 리턴한다.
=> 데이터를 사용하는 애플리케이션을 변경하지 않고, 스키마를 변경하더라도 에러나 예외가 발생하지 않는다.
다만 주의점이 있는데,
- 직렬화할 떄 사용한 스키마와 역직렬화시 사용한 스키마가 호환되어야한다.
- 역직렬화시, 직렬화할 떄 사용한 스키마 정보가 있어야한다.
카프카에서 에이브로 레코드 사용하기
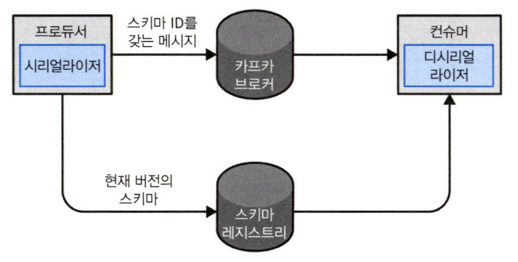
- 스키마 레지스트리(Schema Registry)
- 여러 오픈소스 구현체 중 하나를 골라서 사용하면 된다.
- 데이터를 쓰기 위해 사용되는 스키마를 저장하는 공간으로, 스키마 ID - 스키마 구조로 저장된다.
- 시리얼라이저와 디시리얼라이저가 실제 데이터를 직렬화/역직렬화를 할 때에는, 스키마 레지스트리에서 스키마 ID로 스키마를 조회해 사용한다.
- 데이터를 쓰기 위해 사용되는 스키마를 저장하는 공간으로, 스키마 ID - 스키마 구조로 저장된다.
Avro 스키마 기반으로 자동 생성된 Customer 클래스를 사용해 전송하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Properties properties = new Properties();
properties.put("bootstrap.servers","localhost:9092");
properties.put("key.serializer","io.confluent.kafka.serializer.KafkaAvroSerializer");
properties.put("value.serializer","io.confluent.kafka.serializer.KafkaAvroSerializer");
properties.put("schema.registry.url",schemaUrl);
String topic = "customerContacts";
Producer<String, Customer> producer = new KafkaProducer<>(properties);
while(true){
Customer customer = CustomerGenerator.getNext();
System.out.println("Generated customer "+ customer.toString());
ProducerRecord<String, Customer> record = new ProducerRecord<>(topic, customer.getName(), customer);
producer.send(record);
}
에이브로를 사용해 생성한 객체를 카프카에 쓰는 방법
- 3~4에이브로를 사용해 객체를 직렬화하기 위해
KafkaAvroSerializer를 사용하는 것을 지정한다. - 5스키마를 실제 저장해 놓는 위치를 가리킨다.
- 9프로듀서에서 우리가 사용할 레코드의 밸류 타입이
Customer임을 지정한다. - 12
Customer클래스는 일반적인 자바 클래스가 아닌, 스키마로부터 생성된 에이브로 특화 객체다. - 14밸류 타입이
Customer인 record를 생성하고Customer를 인수로 전달한다. - 15record를 전송하면, 이제
KafkaAvroSerializer가 알아서 해준다.
GenericRecord를 사용하여 Avro 스키마를 직접 정의하고 활용해 전송하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
Properties properties = new Properties();
properties.put("bootstrap.servers","localhost:9092");
properties.put("key.serializer","io.confluent.kafka.serializer.KafkaAvroSerializer");
properties.put("value.serializer","io.confluent.kafka.serializer.KafkaAvroSerializer");
properties.put("schema.registry.url",schemaUrl);
String topic = "customerContacts";
Producer<String, Customer> producer = new KafkaProducer<>(properties);
String schemaString =
"{\"namespace\": \"customerManagement.avro\", " +
"\"type\": \"record\", " +
"\"name\": \"Customer\", " +
"\"fields\": [" +
"{\"name\": \"id\", \"type\": \"int\"}," +
"{\"name\": \"name\", \"type\": \"string\"}," +
"{\"name\": \"email\", \"type\": [\"null\",\"string\"], " +
"\"default\":\"null\" }" +
"]}";
Schema.Parser parser = new Schema.Parser();
Schema schema = parser.parse(schemaString);
for (int nCustomers = 0; nCustomers < customers; nCustomers++) {
String name = "exampleCustomer" + nCustomers;
String email = "example" + nCustomers + "@example.com";
GenericRecord customer = new GenericData.Record(schema);
customer.put("id", nCustomers);
customer.put("name", name);
customer.put("email", email);
ProducerRecord<String, GenericRecord> data = new ProducerRecord<>("customerContacts", name, customer);
producer.send(data);
}
에이브로를 사용해 생성한 객체를 카프카에 쓰는 방법
- 1~9위 예제의 내용과 같다.
- 12~21Kafka에 보낼 데이터 구조를 Avro 스키마로 정의한다.
- 23~24Avro의
Schema.Parser()를 사용하여 JSON 문자열 형태의 Avro 스키마를 Schema 객체로 변환한다. - 27~33전송할 데이터를 Avro의 GenericRecord 객체를 사용하여 Kafka로 보낼 데이터 저장하고 전송한다.
파티션
우리가 지금까지 본 ProducerRecord는 토픽, 키, 밸류 값을 포함한다. 이 때, 키의 역할은 그 자체로 메시지에 함께 저장되는 추가적인 정보이기도 하고, 하나의 토픽에 속한 여러개의 파티션 중 해당 메시지가 저장될 파티션을 결정짓는 기준점이기도하다.
저장될 파티션을 결정짓는 기준점에서의 키
- 키가
null일 때 - 파티션은 랜덤으로 저장된다.
- 각 파티션별로 저장되는 메시지 수의 균형을 위해 라운드 로빈 알고리즘이 사용되는데, 카프카 2.4버전부터 기본파티셔너는 접착성을 위해 라운드 로빈 알고리즘을 사용한다.
- 키가
접착성이란 무엇이고 왜 필요한가? 0번 - P0, 3번 - P4은 키값이 있어 지정된 위치로 저장되어야하고, 나머지는 키값이
null인 데이터들이 있고 한 번에 브로커에 전송될 수 있는 메시지의 수가 4개 라는 상황일때, 접착성이 처리의 유무에 대한 그림이다.접착성이 없는 경우 키값이
null인 메시지들은 라운드 로빈 방식으로 배치되게 된다. 접착성이 있는 경우 키값이null인 메시지들은 일단 키값이 있는 메시지에 따라붙은 다음에 라운드 로빈 방식으로 배치된다. 이렇게 하면 보내야하는 요청의 수가 5개에서 3개로 줄어들게 된다.
- 키가
null이 아닐 때 - 키값을 해시한 결과를 기준으로
hash(key) % num_partitions을 계산하여 파티션을 선택한다.- 특정한 파티션에 장애가 발생한 상태인데, 해당 파티션에 데이터를 쓰려고 하면 에러가 발생한다.
- 키가
파티셔너 종류
- 기본 파티셔너: 위에서 설명한 내용과 같이 동작
- RoundRobinPartitioner: 키의 유무에 관계없이, 무조건 라운드 로빈 방식으로 파티션을 할당
- UniformStickyPartitioner: 키의 유무에 관계없이, 똑같이 일정한 메시지 배치를 같은 파티션에 보내고, 배치가 가득 차면 다음 파티션을 선택
커스텀 파티셔너 구현하기 - 코드로 이해하기
만약, 전체 데이터에서 특정 키에대한 데이터의 내용이 많은 비중을 차지하고 있거나 특정 키에 대한 내용만 따로 분리해 관리하고싶다면 커스텀 파티셔너를 구현해 사용할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.record.InvalidRecordException;
import org.apache.kafka.common.utils.Utils;
public class BananaPartitioner implements Partitioner {
public void configure(Map<String, ?> configs) {}
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if((keyBytes == null) || (!(key instanceof String))) {
throw new InvalidRecordException("We expect all messages to have customer name as key");
}
if(((String) key).equals("test")) {
return numPartitions - 1;
}
return Math.abs(Utils.murmur2(keyBytes)) % (numPartitions - 1);
}
public void close() {}
}
커스텀 퍄티셔너의 예시
- 8이 예제에서는 작성하지 않았지만, 설정해야하는 값이 있다면, 이 메서드로 경유해서 받는것이 좋다.
- 18~20우리가 원한, 특정 키에 대한 내용만 마지막 파티션에 모이도록 하는 로직을 작성했다.
- 22그 외에 데이터들은 키의 해시값을 기반으로하는 원래 동작으로 파티션이 지정되도록 했다.
헤더
- 헤더
- 순서가 있는 키/밸류의 쌍의 집합으로 구현되어있고, 키는 언제나
String이어야하지만 밸류는 직렬화된 객체라도 상관없다.- 카프카 레코드의 키/밸류값을 건드리지 않고 추가 메타데이터를 심을 때 사용한다.
- 주된 용도는 메시지의 전달 내용을 기록하는 것으로, 데이터가 생성된 곳의 정보를 저장해 메시지를 라우팅하거나 출처를 추적할 수 있게 해준다.
- 카프카 레코드의 키/밸류값을 건드리지 않고 추가 메타데이터를 심을 때 사용한다.
코드로 이해하기
1
2
3
ProducerRecord<String, String> record = new ProducerRecord<>("Customer", "Product", "France");
record.headers().add("rpivacy-level","YOLO".getBytes(StandardCharsets.UTF_8));
헤더를 추가하는 방법
인터셉터
- 인터셉터
- 카프카 클라이언트의 코드를 수정하지 않고, 모든 애플리케이션에서 동일한 동작을 하도록 수정해야한다면 인터셉터를 사용할 수 있다.
- 일반적인 사용사례로는 모니터링, 정보 추적, 표준 헤더 삽입 등이 있고, 데이터 전달 경로를 추적하거나 민감한 정보를 삭제 처리하는 등의 용도로도 사용될 수 있다.
주요 메서드
ProducerRecord<K, V> onSend(ProducerRecord<K, V> record)- 프로듀서가 레코드를 브로커로 보내기 전, 직렬화 되기 전에 호출된다.
- 이때 반환되는 레코드가 직렬화되어 카프카로 보내진다.
- 레코드의 정보를 보거나 고칠 수 있다.
- 이때 반환되는 레코드가 직렬화되어 카프카로 보내진다.
void onAcknowledgement(RecordMetadata metadata, Exception exception)- 카프카 브로커가 보낸 응답을 클라이언트가 받았을 때 호출된다.
- 보낸 응답을 변경할 수는 없지만, 그 안에 담긴 정보는 읽을 수 있다.
코드로 이해하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
public class CountingProducerInterceptor implements ProducerInterceptor {
ScheduledExecutorService executorService = Executors.newSingleThreadScheduledExecutor();
static AtomicLong numSent = new AtomicLong(0);
static AtomicLong numAcked = new AtomicLong(0);
public void configure(Map<String, ?> map) {
Long windowSize = Long.valueOf((String) map.get("counting.interceptor.window.size.ms"));
executorService.scheduleAtFixedRate( CountingProducerInterceptor::run, windowSize, windowSize, TimeUnit.MILLISECONDS);
}
public ProducerRecord onSend(ProducerRecord producerRecord) {
numSent.incrementAndGet();
return producerRecord;
}
public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) {
numAcked.incrementAndGet();
}
public void close() {
executorService.shutdownNow();
}
public static void run() {
System.out.println(numSent.getAndSet(0));
System.out.println(numAcked.getAndSet(0));
}
}
프로듀서 인터셉터의 예시
- 7~10
ProducerInterceptor는Configurable인터페이스를 구현하기 때문에,configure()를 재정의해서 다른 메서드가 호출되기전에 뭔가를 설정하는 것이 가능하다. - 12~15레코드 전송시 전송된 레코드 수를 증가시키고, 레코드는 그대로 전송한다.
- 17~19카프카가 ack응답을 보내면, 응답 수를 증가시킨다.
- 21~23프로듀서에
close()가 호출 때 호출되며 인터셉터의 내부 상태를 정리하도록 한다.
- AtomicLong이란?
- 멀티스레드 환경에서 AtomicLong은 내부적으로 CAS(Compare-And-Swap)연산을 사용해 안전하게(long 타입) 값을 업데이트할 수 있도록 보장하는 동기화된 변수이다.
java.util.concurrent.atomic에 포함되어 있다.synchronized키워드 없이도 값을 증가/감소/설정할 수 있습니다.
kafka-console-producer.sh 툴과 함께 사용하려면
- 인터셉터를 컴파일해
jar파일로 만든다음.classpath에 추가한다1
export CLASSPATH=$CLASSPATH:[경로].[컴파일한 인터셉터 파일명].jar
- 설장파일을 생성한다.(예시로 파일명을
producer.config라 하자)1 2
interceptor.classes=[작성한 인터셉터의 패키지명].[작성한 인터셉터의 클래스명] counting.interceptor.window.size.ms=10000
- 애플리케이션을 실행 시킬 때, 2번 과정에서 생성한 설정 파일을 포함해 실행한다.
1
bin/kafka-console-procuder.sh --broker-list localhost:9092 --topic interceptor-test --producer.config producer.config
쿼터, 스로틀링
프로듀서의 전송 속도가 브로커의 처리 속도보다 빠르다면,
- 프로듀서는 내부 버퍼가 점점 쌓이게 된다.
- 버퍼가 줄어들지 않고 늘어나다 가득 차게 된다.
- 버퍼에 공간이 없어
send()호출시, 블로킹 상태가 된다.
이러한 문제가 발생하지 않으려면, 브로커가 처리할 수 있는 용량과 프로듀서가 전송하려는 속도를 계획적으로 모니터링하고 속도를 조절해야할 필요가 있다. 이를 위해 카프카 브로커에는 쓰기/읽기 속도를 제한할 수 있는 기능이 있다.
- 쓰기 쿼터: 클라이언트가 데이터를 전송하는 속도를 초당 바이트 수 단위로 제한
- 읽기 쿼터: 클라이언트가 데이터를 받는 속도를 초당 바이트 수 단위로 제한
- 요청 쿼터: 브로커가 요청을 처리하는 시간을 비율 단위로 제한
대상은 client.id로 지정하거나,특정 사용자에 대해 지정하는 등의 방식으로 지정 가능하며, 사용자에 대한 설정은 보안기능과 클라이언트 인증 기능이 활성화되어 있는 클라이언트에서만 작동한다.
코드로 이해하기
1
2
3
bin/kafka-configs --bootstrap-server localhost:9092 --alter --add-config 'producer_byte_rate=1024' --entity-name clientC --entity-type clients
bin/kafka-configs --bootstrap-server localhost:9092 --alter --add-config 'producer_byte_rate=1024,consumer_byte_rate=2048' --entity-name user1 --entity-type users
bin/kafka-configs --bootstrap-server localhost:9092 --alter --add-config 'consumer_byte_rate=2048' --entity-type clients
프로듀서 인터셉터의 예시
- 1clientC 클라이언트(=client-id값으로 지정)의 쓰기 속도를 초당 1024 바이트로 제한한다.
- 2user1(=인증 주체)의 쓰기 속도를 초당 1024바이트로, 읽기 속도는 초당 2048바이트로 제한한다.
- 3모든 사용자의 읽기 속도를 초당 2048바이트로 제한하되, 기본 설정값을 덮어쓰고 있는 사용자에 대해서는 예외로 한다.
확인하는 방법
클라이언트 입장에서는 JMX 메트릭을 통해서 스로틀링 작동 여부를 확인할 수 있다.
produce-throttle-time-avgproduce-throttle-time-maxfetch-throttle-time-avgfetch-throttle-time-max