Java Standard - 컬렉션 프레임웍
...
JDK 1.2이전에는 서로 각자 다른 방식으로 처리 했어야함, 컬렉션 프레임웍의 등장으로 표준화된 방식으로 다룰 수 있도록 체계화 됨 의미
- 컬렉션: 다수의 데이터, 데이터 그룹
- 프레임웍: 표준화된 프로그래밍 방식
- 컬렉션 프레임웍: 데이터 군을 저장하는 클래스들을 표준화한 설계
컬렉션 프레임웍의 핵심 인터페이스
컬렉션 프레임웍의 핵심 인터페이스
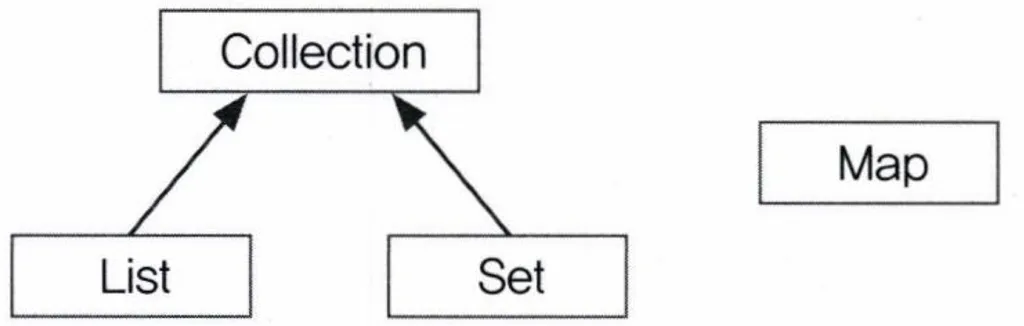 데이터 그룹을 크게 3가지로 나누었는데, 그 중 List와 Set의 공통부분만 다시 뽑아 Collection을 정의
데이터 그룹을 크게 3가지로 나누었는데, 그 중 List와 Set의 공통부분만 다시 뽑아 Collection을 정의
종류
- List: 순서 O, 중복 O
- Set: 순서 X, 중복 X
- Map: key와 value가 쌍으로 이루어짐, key는 중복 X, value는 중복 O, 순서 X
특징
- 컬렉션 프레임웍의 모든 컬렉션 클래스는 List, Set, Map 중 하나를 구현
- Vector, Stack, Hashtable, Properties와 같은 클래스는 컬렉션 프레임웍 이전의 것
- Vector, Hashtable같은 기존의 컬렉션 클래스들은 호환을 위해, 설계를 변경한 후 남겼지만, 가능하면 사용하지 않는 것이 좋음
Collection 인터페이스
특징
- List와 Set의 조상인 인터페이스
- 컬렉션을 다루는데 가장 기본적인 메서드를 정의
메서드 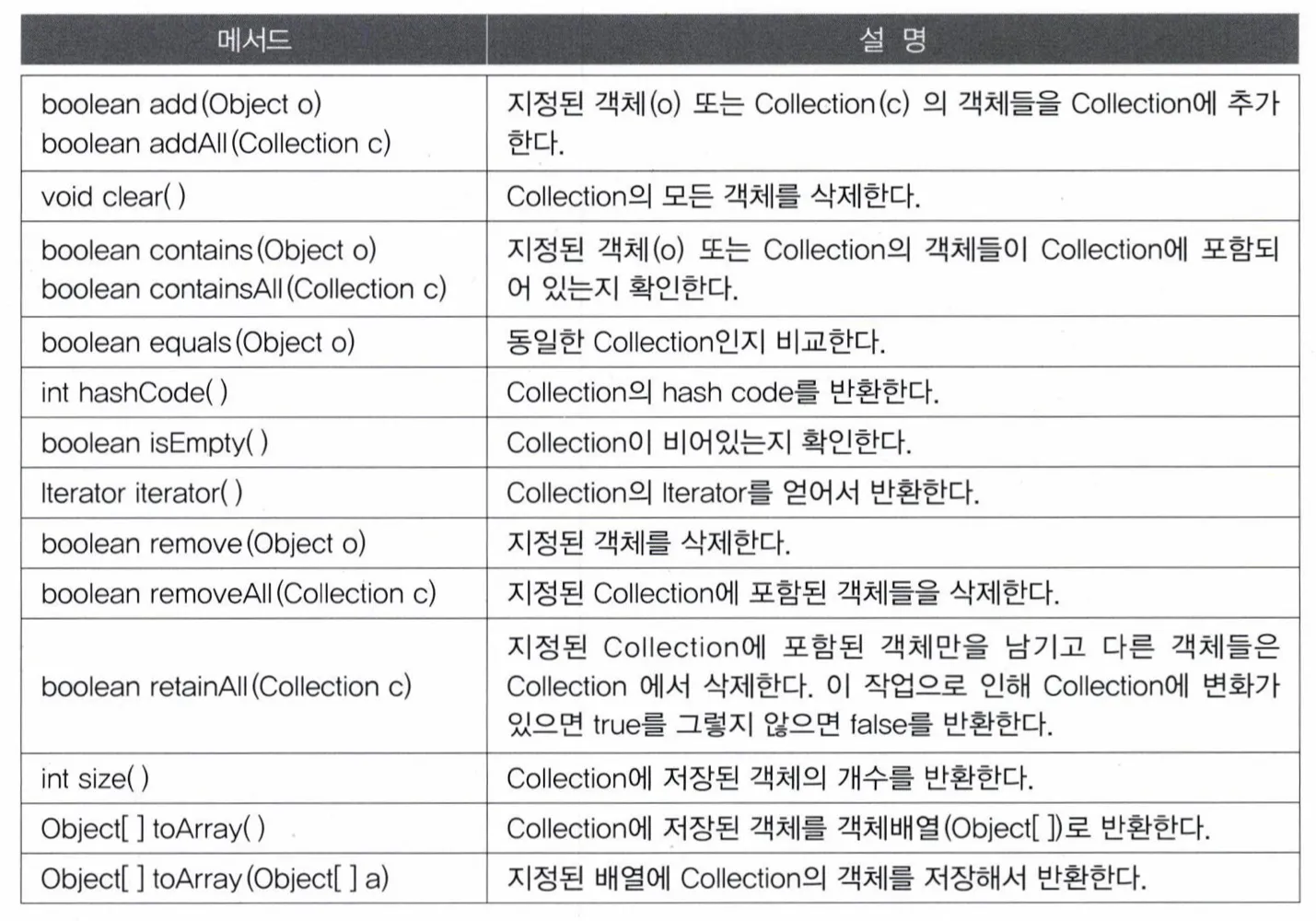
List 인터페이스
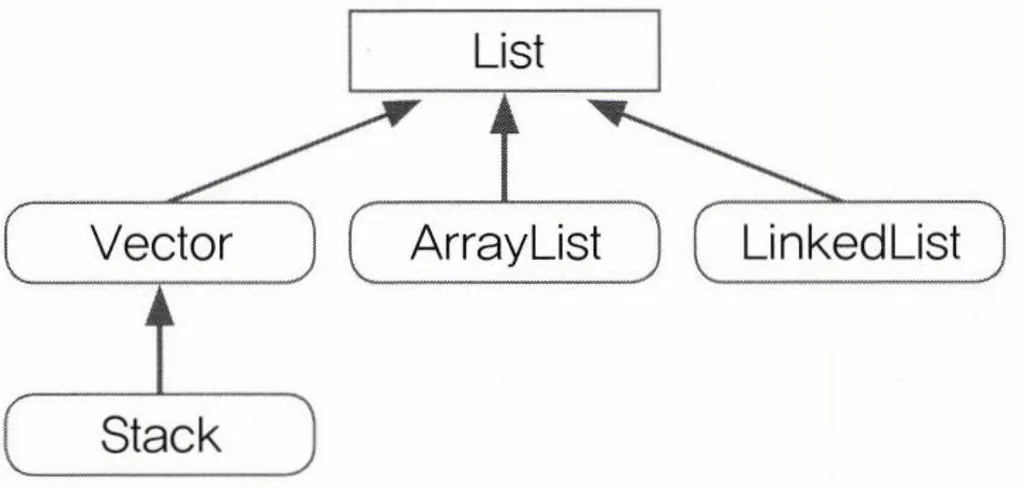
특징
- 중복을 허용, 저장순서가 유지
메서드 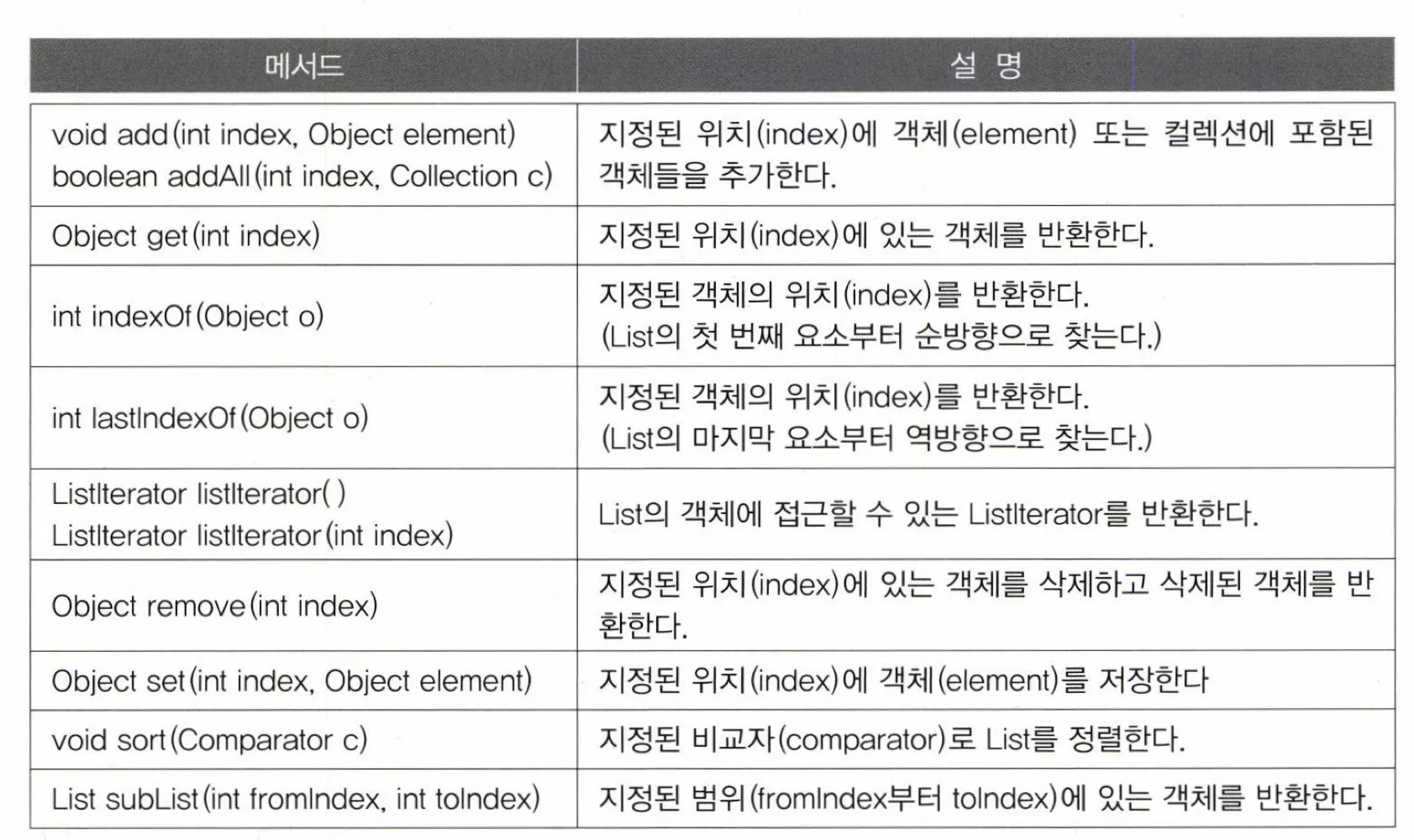
- Collection 인터페이스에서 상속받은 내용 제외하고 추가된 부분만
Set 인터페이스
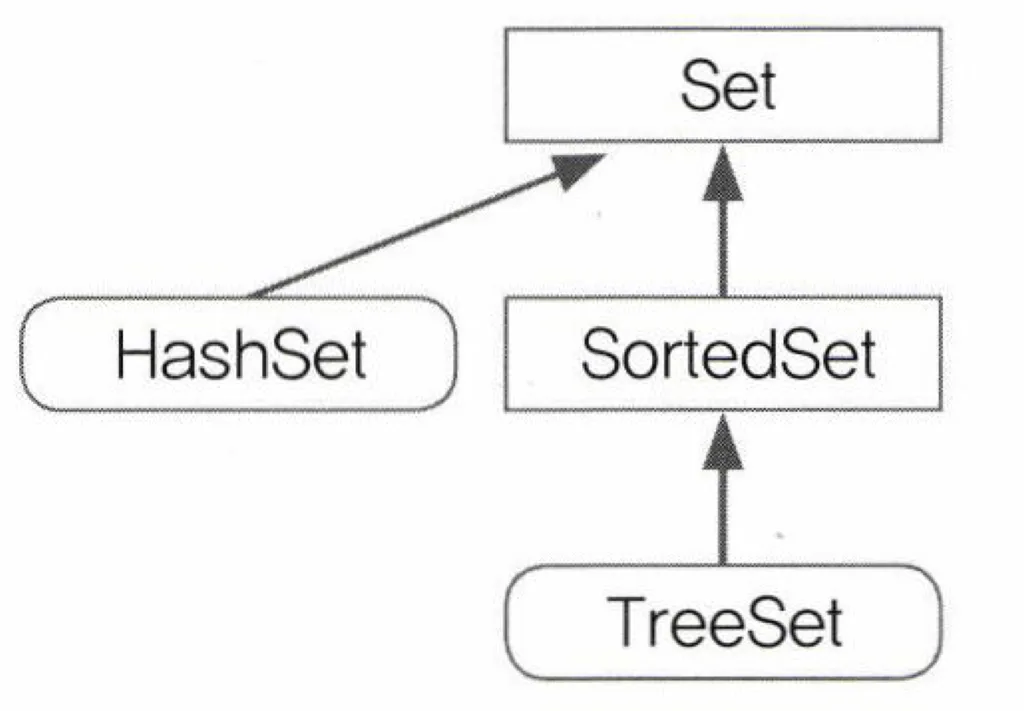
특징
- 중복을 허용하지 않음, 저장순서가 유지되지 않음
Map 인터페이스
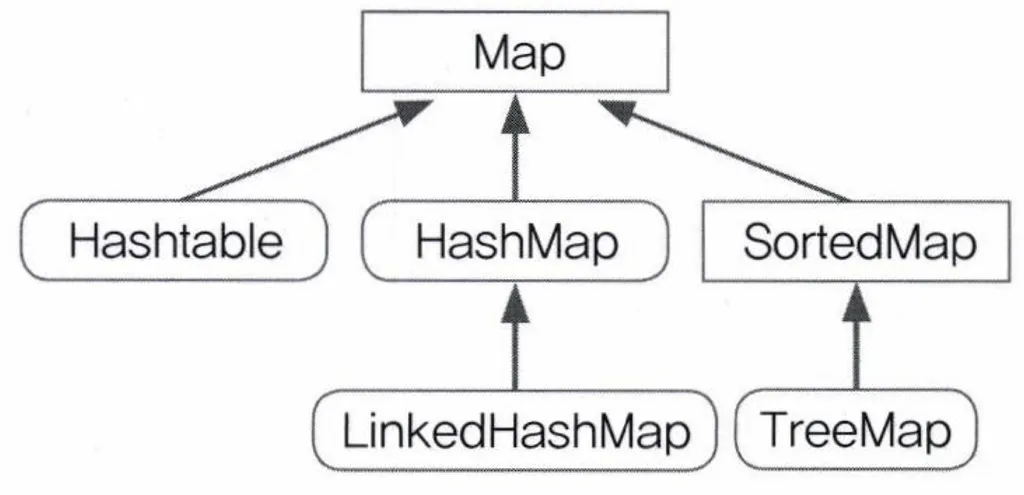
특징
- key와 value가 하나의 쌍으로 묶여서 저장
- 키는 중복이 불가능, 값은 중복이 가능 → 중복된 키로 저장하면 마지막에 저장한 값만 남음
메서드 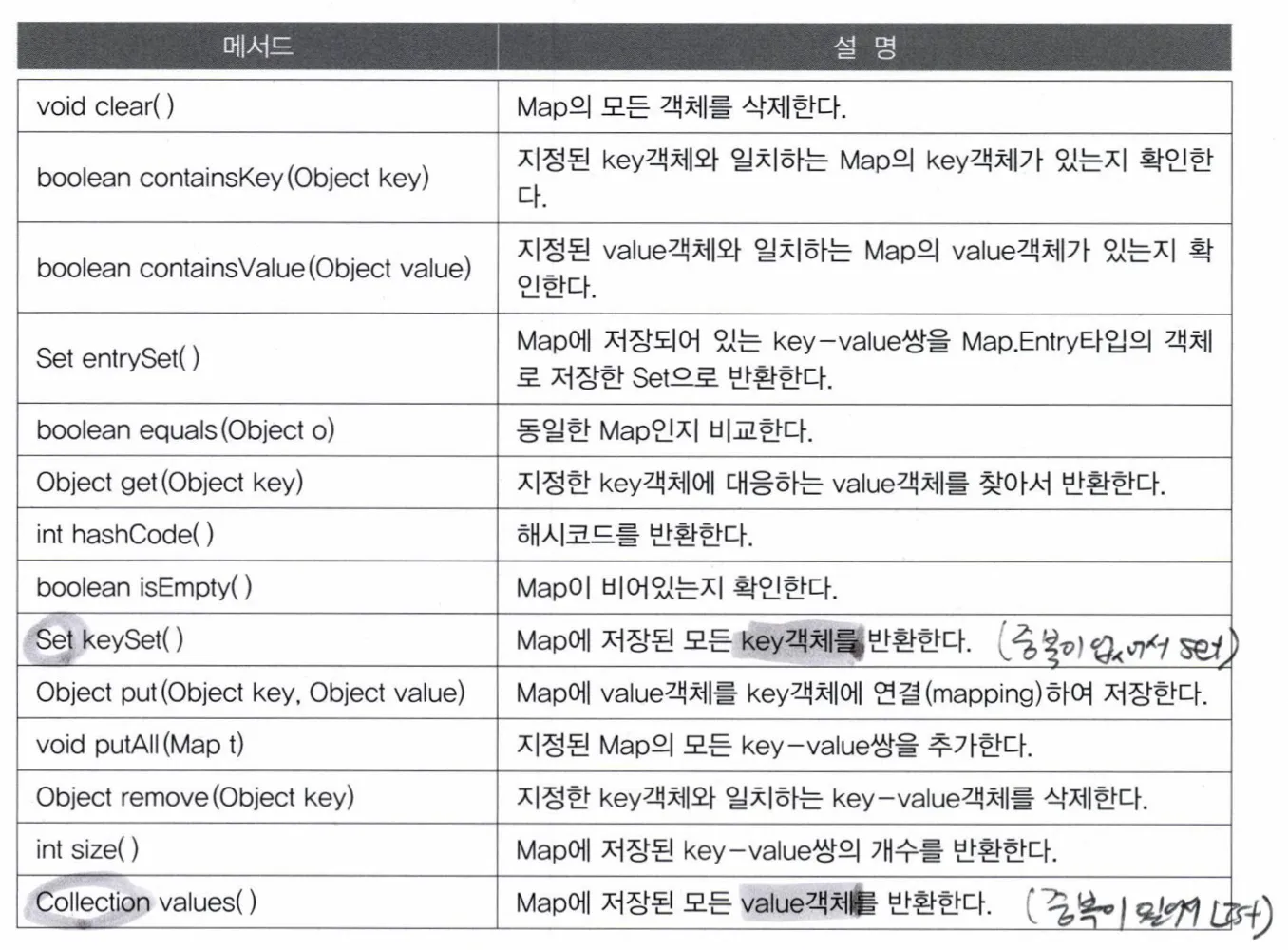
Map.Entry인터페이스
특징
- Map인터페이스의 내부 인터페이스
- key-value쌍으로 다루기 위해 정의함
- Map 인터페이스를 구현하는 클래스는 Map.Entry인터페이스도 함께 구현해야함
예시 코드 

내부 인터페이스(inner interface) 내부 클래스와 같이 인터페이스 안에 내부 인터페이스를 정의하는 것이 가능함
ArrayList
특징
- List 인터페이스 구현 = 순서 O, 중복 O
- 기존의 Vector를 개선한 것, Vector 구현원리와 기능적인 측면에서 동일 → ArrayList 사용
- Object배열을 이용, 데이터를 순차적으로 저장
→ 배열 공간이 없으면 새로운 배열을 생성해 복사하는 방식으로 동작 ⇒ 이 과정에서 시간이 많이 소요됨
메서드
- 생성자
ArrayList(): 크기가 10인 ArrayList생성ArrayList(int initialCapacity): 지정된 초기용량을 갖는 ArrayList생성ArrayList(Collection c): 주어진 컬렉션이 저장된 ArrayList생성
- 저장
add(): 마지막이나 지정된 위치에 객체 추가addAll(): 주어진 컬렉션을 저장set(): 주어진 위치에 객체를 저장, 추가하지 않고 덮어씌움
- 삭제
clear(): ArrayList를 모두 비움remove(): 지정된 위치에 있는 객체를 반환하고, 삭제removeAll(): 컬렉션에 저장된 동일한 것만 제거retainAll(): 컬렉션에 저장된 동일한 것만 남기고 제거
- 조회
get(): 저장된 객체를 반환indexOf(): 저장된 객체의 위치를 반환lastIndexOf(): 저장된 객체의 위치를 반환, index를 끝부터 역방향으로 검색해서 반환size(): ArrayList안에 저장된 객체의 개수를 반환
- 비교
contains(): 지정된 객체가 ArrayList안에 있는지 확인isEmpty(): ArrayList가 비어있는지 확인
- 그 외
trinToSize(): 용량을 크기게 맞게 줄임ensureCapacity(): ArrayList용량이 최소한 지정값이 되도록 함
용량(capacity)과 크기(size)
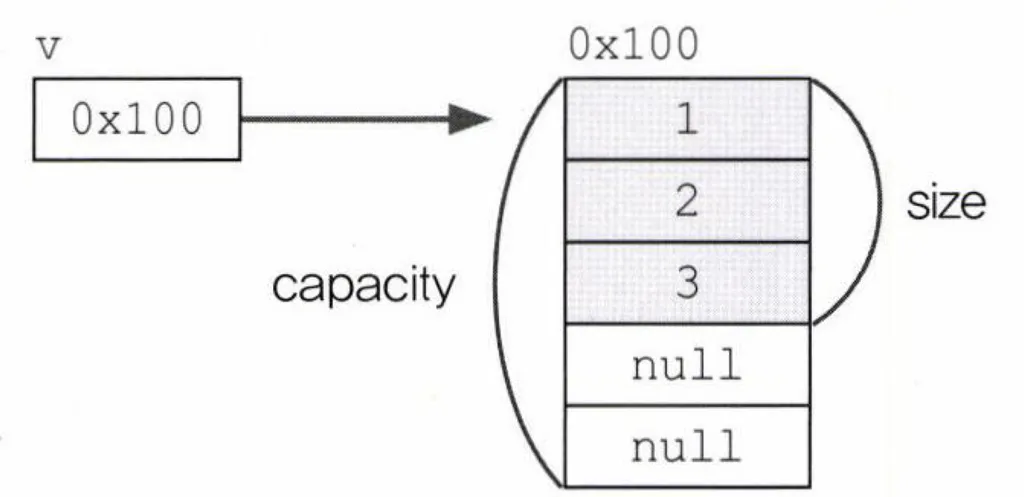
- 용량: 값을 담을 수 있는 정도
- 크기: 값이 담겨져 있는 정도
용량 < 크기 인 상황이 되면, 자동으로 용량을 현재의 2배로 늘려서 작업을 진행
삭제
예제: data[2]을 삭제하는 과정 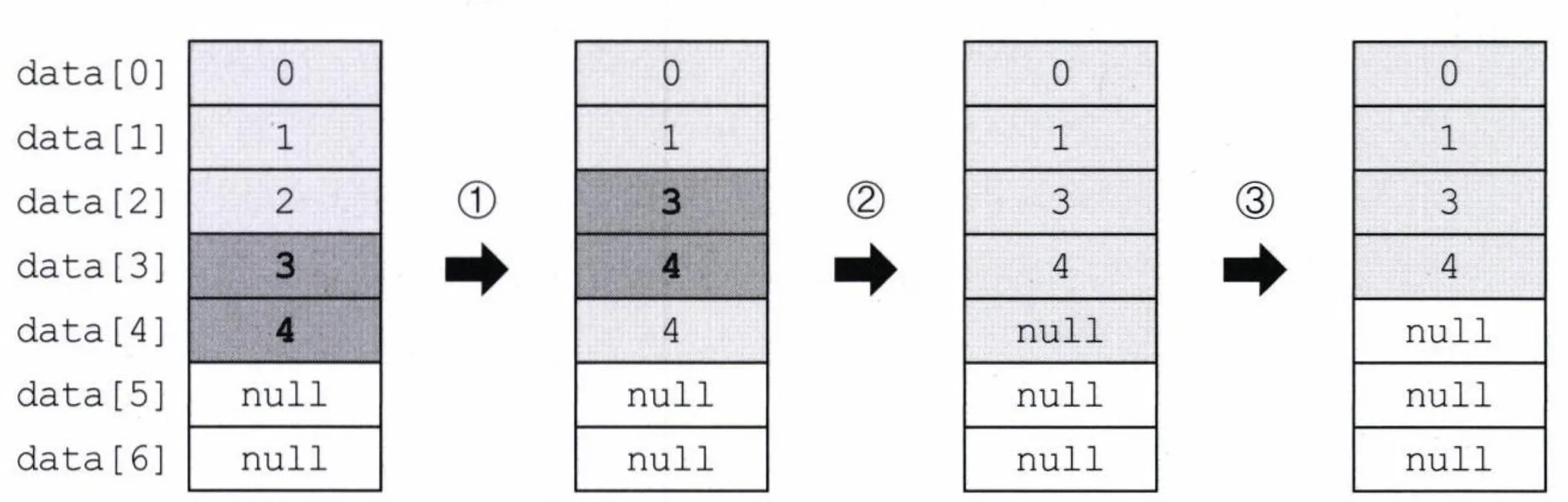
- 삭제할 데이터 다음에 있는 데이터들을 복사해서 삭제할 데이터 위치로 덮어씀
System.arraycopy(data, 3, data, 2, 2)data[3]에서 data[2]로 2개의 데이터를 복사 - 마지막 데이터를 null로 저장
data[size-1] = null; - size가 줄었으므로 size 줄임
size—;
⇒ 순차적인 값의 추가와 삭제는 System.arraycopy()를 호출하지 않아 빠르지만, 중간의 값을 추가하거나 삭제하면 System.arraycopy() 를 호출하기 때문에 오래걸리고, 데이터가 많을 수록 오래걸린다.
장점과 단점
- 장점: 데이터를 읽어오고 저장할 때 효율이 좋음
- 단점: 용량을 변경할 때에는 배열을 새로 만들고 값을 복사해야해서 효율이 떨어짐
LinkedList
특징
- 불연속적으로 존재하는 데이터를 서로 연결한 형태로 구성
- 서로 연결된 구성 모양에 따라 여러 linkedList가 있음
- 더블 링크드 리스트, 링크드 리스트, 더블 써큘러 링크드 리스트 등
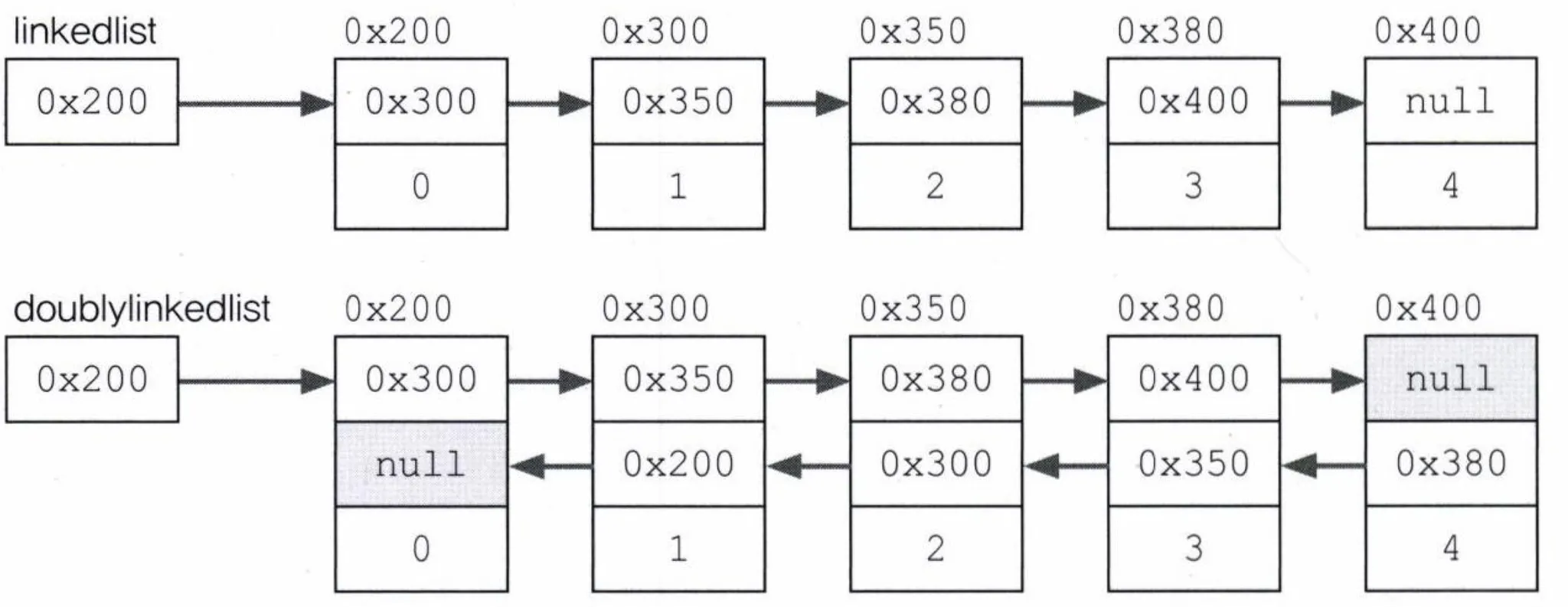
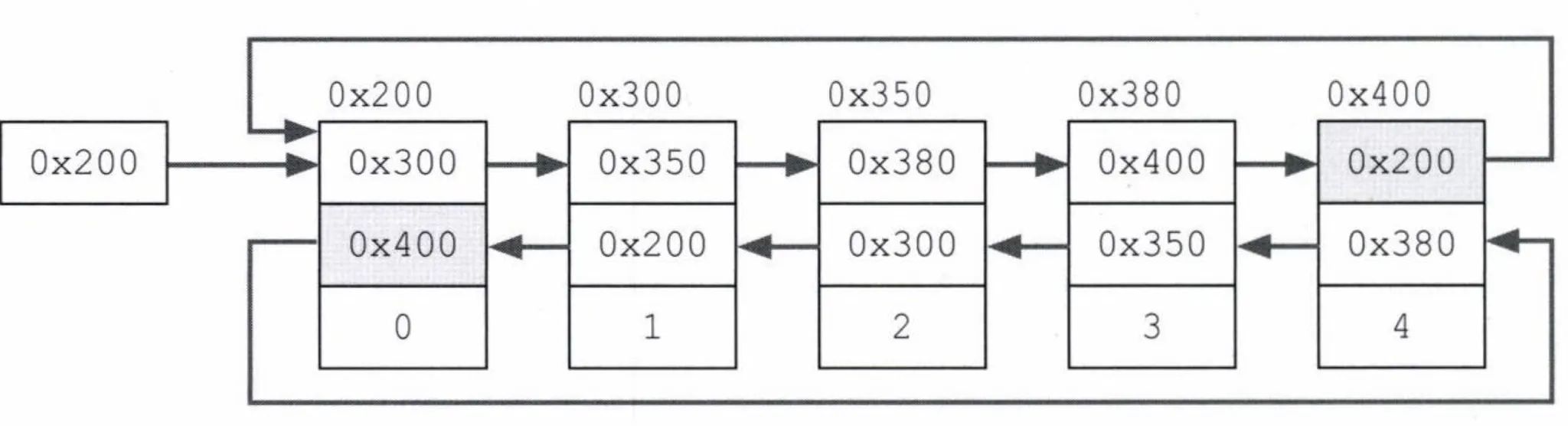
- 중간의 객체를 추가하거나 삭제시 서로 연결하는 참조값만 변경해주면 되기 때문에 처리 속도가 빠름
메서드
- 생성자
LinkedList(): LinkedList생성LinkedList(Collection c): 주어진 컬렉션을 포함하는 LinkedList객체를 생성
- 저장
add(): 마지막이나 지정된 위치에 객체 추가addAll(): 주어진 컬렉션을 저장set(): 주어진 위치에 객체를 저장, 추가하지 않고 덮어씌움offer(): 객체를 끝에 저장push(): 맨 앞에 객체를 저장
- 삭제
clear(): ArrayList를 모두 비움remove(): 지정된 위치에 있는 객체를 반환하고, 삭제removeAll(): 컬렉션에 저장된 동일한 것만 제거retainAll(): 컬렉션에 저장된 동일한 것만 남기고 제거poll(): 첫번째 위에치 있는걸 반환하고, 삭제pop(): 첫번째 위에치 있는걸 반환하고, 삭제
- 조회
get(): 저장된 객체를 반환indexOf(): 저장된 객체의 위치를 반환lastIndexOf(): 저장된 객체의 위치를 반환, index를 끝부터 역방향으로 검색해서 반환size(): ArrayList안에 저장된 객체의 개수를 반환peek(): 첫번째 요소를 반환
- 비교
contains(): 지정된 객체가 ArrayList안에 있는지 확인isEmpty(): ArrayList가 비어있는지 확인
- 그 외
trinToSize(): 용량을 크기게 맞게 줄임ensureCapacity(): ArrayList용량이 최소한 지정값이 되도록 함
ArrayList와 LinkedList 비교
- 순차적으로 추가 및 삭제하는 경우: ArrayList가 빠름 단 조건은 ArrayList의 공간이 부족하지 않았을 경우에만, ArrayList의 공간이 부족해 추가적으로 공간을 만들어야하는 상황이 생긴다면, LinkedList가 더 빠를 수 있음
- 중간에 있는 데이터를 추가 및 삭제하는 경우: LinkedList가 빠름 LinkedList는 중간 요소의 각 요소간의 연결만 변경해주면 되기 때문에 처리 속도가 빠르지만, ArrayList는 무조건 각 요소들을 재배치해야하기 때문에 느림
- 각 데이터의 접근 시간: ArrayList가 빠름 접근해야하는 데이터의 주소를 계산해서 접근하면 됨 (배열의 주소 + 접근할 인덱스 * 데이터 타입 크기) ⇒ 데이터를 저장할 때는 ArrayList, 작업을 할 때에는 LinkedList를 이용하면 가장 좋은 효율을 얻을 수 있음
Stack과 Queue
구조
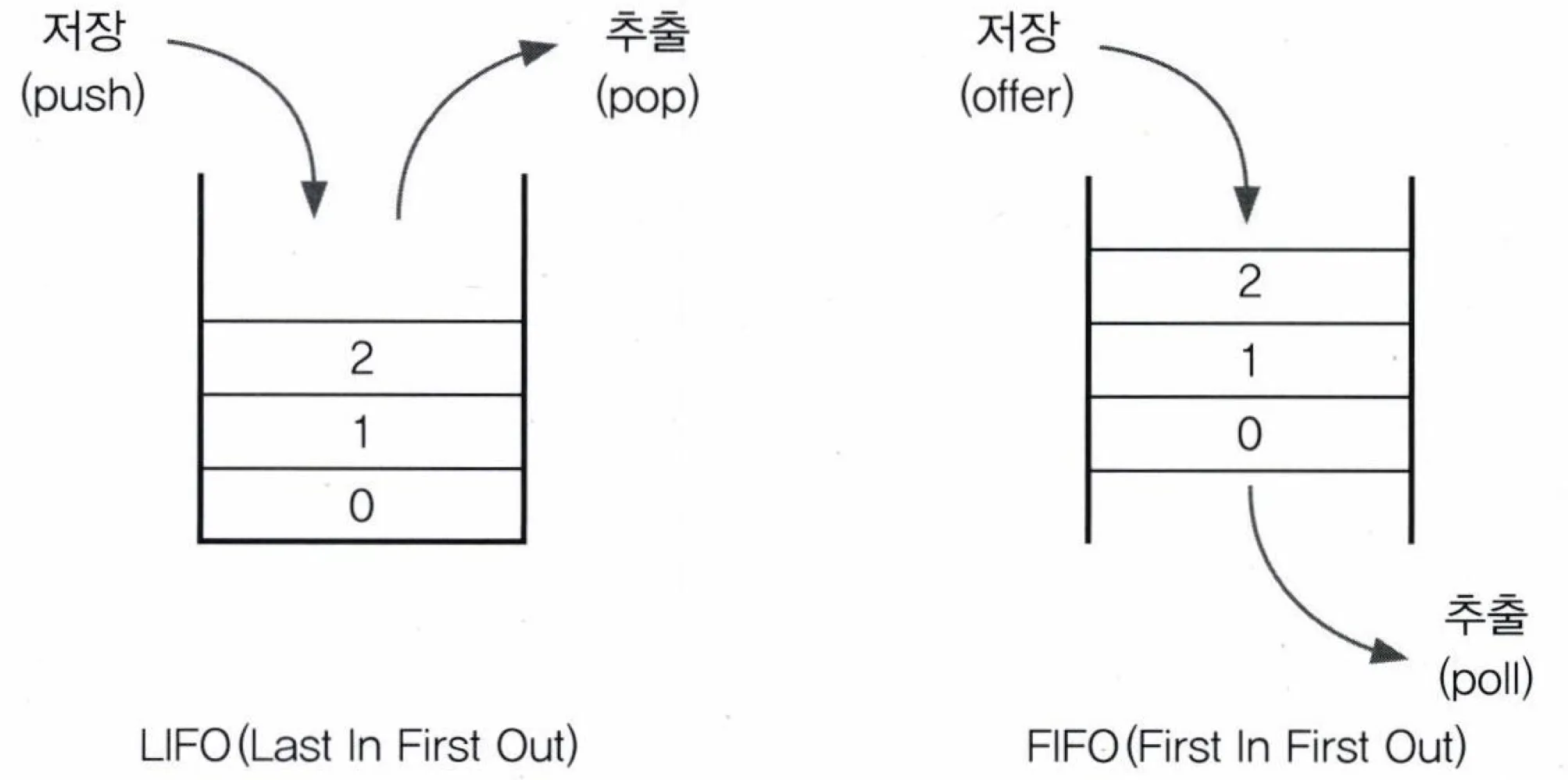
- Stack
- 마지막에 저장한 데이터를 가장 먼저 꺼내게 되는 LIFO구조
- ArrayList로 구현하는 것이 적합
- Stack클래스로 구현해 제공
- 예: 수식계산, 수식 괄호검사, 워드프로세서의 undo/redo, 웹브라우저의 뒤로/앞으로
- Queue
- 처음 저장한 데이터를 가장 먼저 꺼내는 FIFO구조
- LinkedList로 구현하는 것이 적합
- Queue인터페이스만 정의, 구현클래스가 여러개 있어 이 중에 하나를 사용하면 됨
- 예: 최근 사용문서, 인쇄작업 대기목록, 버퍼(buffer)
메서드
- Stack
empty(): 비어있는지 알려줌peek(): 마지막 객체를 반환, 값을 미제거pop(): 마지막 객체를 반환, 값을 제거push(): 객체를 저장함search(): 주어진 객체를 찾아 그 위치를 반환
- Queue
element(): 마지막 객체를 반환, 값은 미제거, 값이 없으면noSuchElementException발생peek(): 마지막 객체를 반환, 값을 미제거remove(): 마지막 객체를 반환, 값을 제거, 값이 없으면noSuchElementException발생poll(): 마지막 객체를 반환, 값을 제거add(): 객체를 저장함, 저장공간 부족시IllegalStateException발생offer(): 객체를 저장함
PriorityQueue
특징
- Queue인터페이스의 구현체 중 하나
- 저장한 순서에 관계 없이 우선순위가 높은 것부터 꺼내게됨
null을 저장할 수 없음,NullPointerException발생- 저장공간으로 배열을 사용
- 각 요소를 힙(heap)이라는 자료구조의 형태로 저장
힙(heap)이란? 이진 트리의 한 종류로 가장 큰 값이나 가장 작은 값을 빠르게 찾을 수 있는 특징을 가짐 JVM의 힙(heap)과는 이름만 같을 뿐 다름
예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
Queue pq new PriorityQueue();
pd.offer(3);
pd.offer(1);
pd.offer(5);
pd.offer(2);
pd.offer(4);
System.out.println(pd);
//결과 [1,2,5,3,4]
Object obj = null;
while((obj = pd.poll()) != null)
System.out.println(obj);
//결과
1
2
3
4
5
예시
- 저장 순서는 3,1,5,2,4 이지만, 출력 결과는 1,2,3,4,5, 내부적으로 가지고 있는 배열의 내용은 1,2,5,3,4
- 내부적으로 가지고있는 순서는 힙이라는 자료구조의 형태로 저장된 것이라서 출력결과와 다름
- 여기서의 우선순위는 int를 Integer로 오토박싱주고, Number의 자손은 자체적으로 숫자를 비교하는 방법을 정의하고 있기 때문에 비교 방법을 정의하지 않아도 해당 방법으로 우선순위가 지정됨
- 만약 위와 달리 객체를 저장하고싶다면, 객체의 크기를 비교할 수 있는 방법도 같이 제공해야함
Deque(Double - Ended Queue)
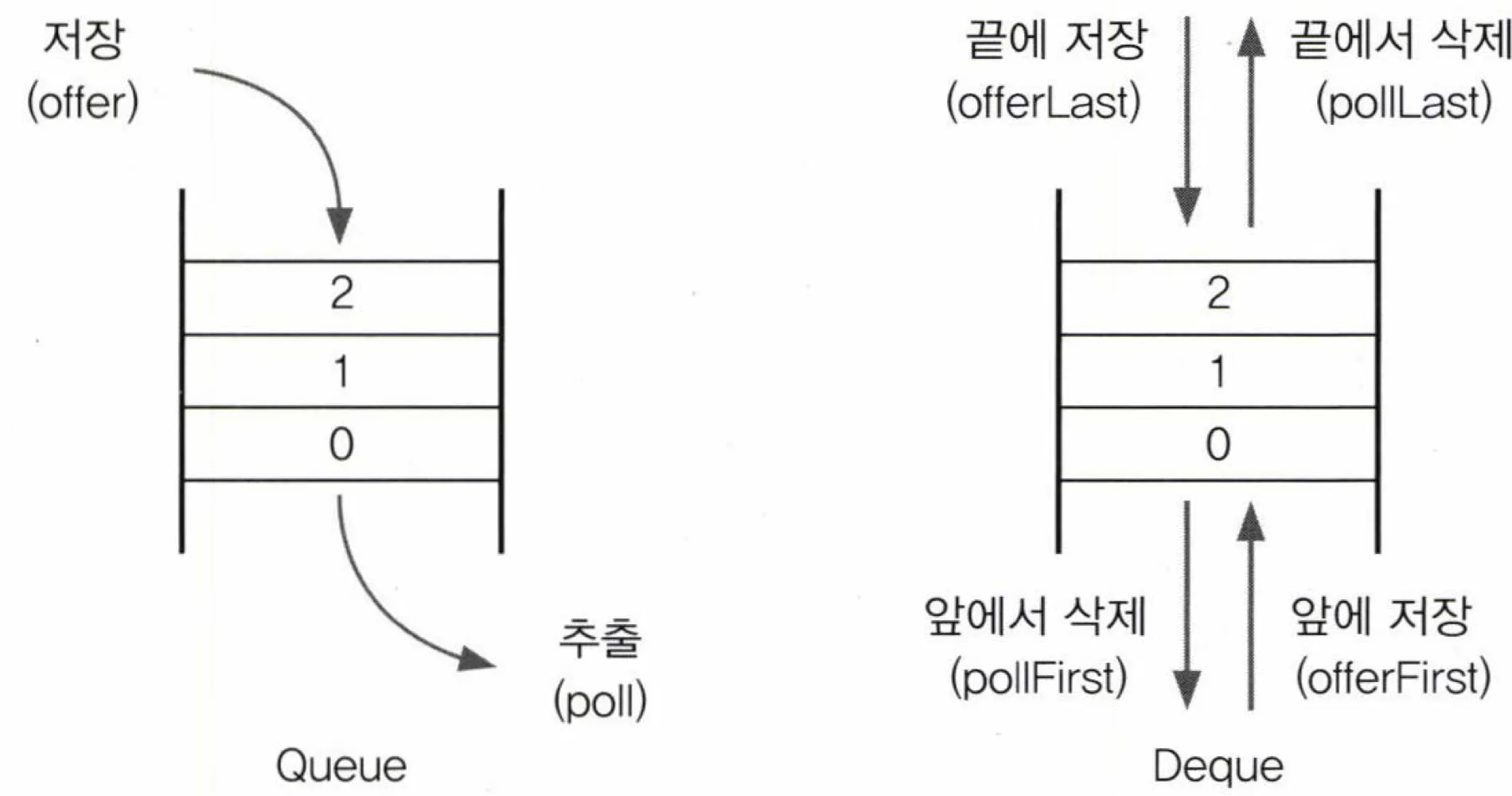
특징
- Queue의 변형된 모양
- 양쪽 끝에서 추가, 삭제가 가능함
- 구현체로는 ArrayDeque와 LinkedList등이 있음
- 스택과 큐를 합쳐놓은것과 같음 = 스택으로도 사용할 수 있고, 큐로도 사용할 수 있음
메서드
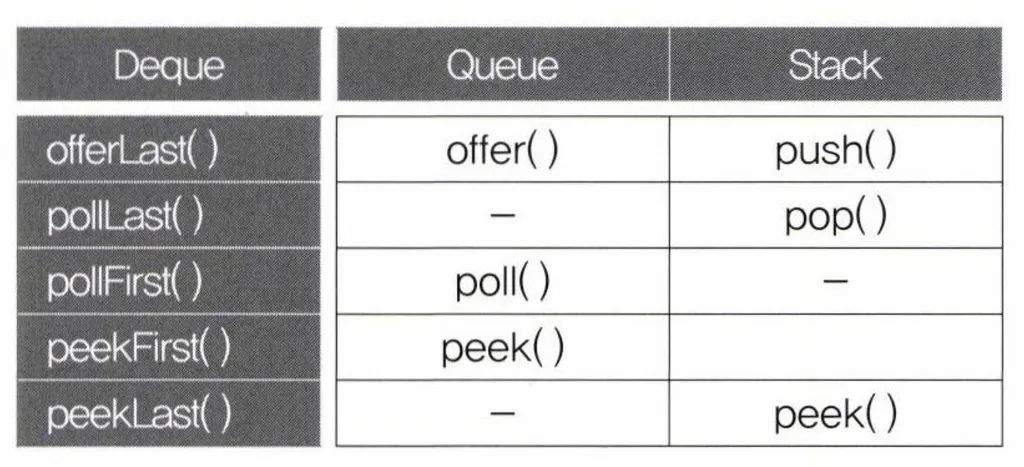
Iterator, ListIterator, Enumeration
Iterator, ListIterator, Enumeration 모두 컬렉션에 저장된 요소를 접근하는데 사용되는 인터페이스
Enumeration → Iterator → ListIterator 순으로 개발 되었음
Iterator
컬렉션 프레임웍: 컬렉션에 저장된 요소들을 읽어오는 방법을 표준화
- 컬렉션에 저장된 각 요소에 접근하는 기능을 가진 Iterator인터페이스를 정의
- Collection인터페이스: Iterator를 반환하는
iterator()를 정의
객체지향의 의미 Iterator를 이용해 컬렉션 요소를 읽어오는 방법을 표준화 → 코드의 재사용성을 높임 이렇게 공통 인터페이스를 정의해 표준을 정의 및 구현함으로써 일관성을 유지 ⇒ 재사용성 극대화 → 객체지향 프로그래밍의 중요한 덕목
특징
- List와 Set 인터페이스를 구현하는 클래으세는
iterator()가 각 특징에 맞게 정의되어있음 - 주로 while문을 이용해 요소들을 읽어올 수 있음
메서드
hasNext(): 읽어올 요소가 남아있는지 확인next(): 다음 요소를 읽어옴, hasNext()를 먼저 호출한 뒤에 사용하는 것이 안전remove(): next()로 읽어온 요소를 삭제, next()로 호출한 뒤 remove()호출해야함(선택적 기능)
예시
1
2
3
4
5
Collection c = new ArrayList();
Iterator it = c.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
참조변수 선언을 ArrayList가 아닌 Collection으로 한 이유
참조변수가 ArrayList 타입 = ArrayList에만 정의된 메서드를 호출했을 수 있음
참조변수가 Collection 타입 = Collection에만 정의된 메서드를 호출함 = Collection에 정의되지 않은 메서드는 호출하지 않음을 의미
⇒ 만약, ArrayList에서 LinkedList로 변경해야하는 상황이 오면 new ArrayList만 new LinkedList로 변경해도 됨! Collection에 정의되지 않은 메서드는 사용하지 않았기 때문에 문제가 발생하지 않음!
Map의 Iterator
- Map인터페이스를 구현한 클래스는 바로 iterator()를 호출할 수 없음(Collection을 상속받지 않아서)
keySet()이나entrySet()의iterator()를 호출해야함- map.keySet() 으로 Set 컬렉션 생성
- Set 컬렉션의 Iterator() 호출로 Iterator생성
합쳐서 하는 것도 가능함
Enumeration
이전 버전의 호환을 위해 남겨놓은 것일 뿐 Iterator의 사용을 권장함
메서드
hasMoreElements(): 읽어올 요소가 남아있는지nectElement(): 다음 요소를 읽어옴
ListIterator
특징
- Iterator를 상속받아 기능을 추가한 것
- List인터페이스를 구현한 컬렉션에서만 사용 가능함
- 양방향으로 이동할 수 있어, 요소간의 이동이 자유로움
ListIterator와 Iterator의 차이
- Iterator: 단방향
- ListIterator: 양방향
메서드
hasNext(): 읽어올 요소가 남아있는지hasPrevious(): 이전 요소가 남아있는지next(): 다음 요소를 읽어옴previous(): 이전 요소를 읽어옴remove():next()나previous()로 읽어온 요소를 삭제함, 선택적기능set():next()나previous()로 읽어온 요소를 지정된 요소로 변경, 선택적기능add(): 컬렉션에 새로운 객체를 추가, 선택적기능nextIndex(): 다음 요소의 인덱스 반환previousIndex(): 이전 요소의 인덱스 반환
❓ 선택적 기능이란? 반드시 구현하지 않아도 되는 기능들을 의미 하지만 그렇다고 해서 구현을 아예 하지 않으면 추상 클래스가 되므로 메서드 body를 구현해야함
{}단순히 이렇게 빈 body를 구현하는 것이 아니라UnsupportedOperationException을 발생시켜 지원하지 않는 함수임을 알리는 것이 좋음 그렇지 않으면 메서드를 호출하는 곳에서 바르게 동작하지 않는 이유를 알 수 없기 때문
cursor와 lastRet
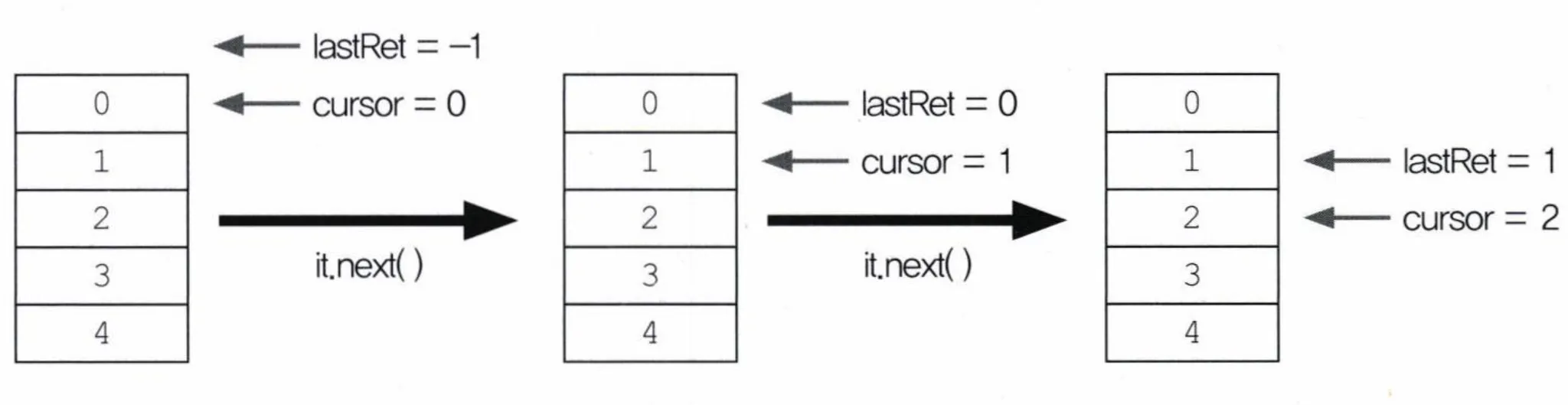
- cursor: 앞으로 읽어 올 요소의 위치를 저장하는데 사용
- lastRet: 마지막으로 읽어온 요소의 위치를 저장하는데 사용
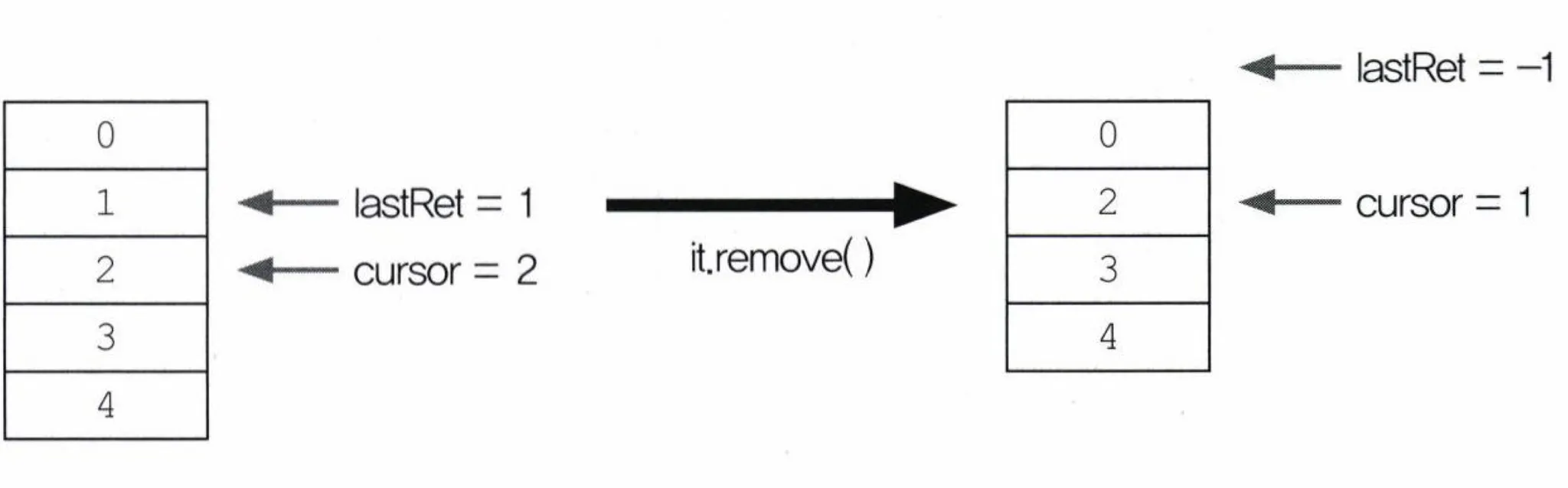
- cursor보다 항상 -1 작은 값이 저장되고,
remove()호출시 -1로 초기화됨
Arrays
배열을 다루는데 유용한 메서드가 정의
복사
copyOf(): 배열 전체 복사copyOfRange(): 배열 일부 복사
채우기
fill(): 모든 요소를 지정된 값으로 채움setAll(): 배열을 채우는데 사용할 함수형 인터페이스를 매개변수로 받음- 람다식으로 지정 하거나 인터페이스를 구현한 객체를 매개변수로 지정
정렬
sort(): 배열을 정렬
검색
binarySearch(): 값을 찾아서 index를 반환, 동일 값이 여러개라면 이 중 어떤 것의 위치인지는 모름
검색의 종류
- 순차검색: 배열의 첫번째 요소부터 순서대로 검색, 시간이 많이 걸림
- 이진검색: 배열의 검색 범위를 절반씩 줄여가며 검색, 속도가 빠름, 정렬되어있어야지 사용가능
비교
equals(): 모든 요소를 비교, 일차원 배열에서 사용가능, 다차원 배열 비교시 주소값 비교가 되어 falsedeepEquals(): 다차원 배열 비교
출력
toString(): 일차원 배열에만 사용할 수 있음deepToString(): 다차원 배열에 사용할 수 있음, 모든 문자열을 재귀적으로 접근
배열을 List로 변환
asList(): 배열을 List로 변환- 추가나 삭제는 할 수 없고 값 변경만 가능한 List로 변환
- 추가 삭제를 하고 싶으면 list를 가지고 다시 collection을 만들어야함
쓰레드와 스트림 관련
parallel~(): 여러 쓰레드가 작업을 나누어 처리spliterator(): 여러 쓰레드가 처리할 수 있게 하나의 작업을 여러 작업으로 작업으로 나누는 Splliterator를 반환stream(): 컬렉션을 스트림으로 변환
Comparator와 Comparable
Comparator와 Comparable 둘 다 인터페이스, 컬렉션을 정렬하는데 필요한 메서드를 정의함
Arrays.sort()등과 같이 사용됨
Comparable
1
2
3
public interface Comparable{
int compareTo(Object o);
}
- 기본 정렬기준을 구현하는데 사용
- java.lang 패키지에 존재
- 같은 타입의 인스턴스끼리 서로 비교할 수 있는 클래스 ex) Integer, String, Date
- Comparable을 구현한 클래스는 정렬이 가능한 것을 의미
Comparator
1
2
3
4
public interface Comparator{
int compare(Object o1, Object o2);
boolean equals(Object obj);
}
- 기본 정렬기준 외 정렬기준 정의시 사용
- java.util 패키지에 존재
- equals()는 기본메서드지만, 오버라이딩이 필요할 수도 있다는 것을 알리기 위해 인터페이스에서 정의함
- String에서는 상수의 형태로 제공함
HashSet
특징
- Set을 수현한 가장 대표적인 컬렉션
- 중복된 요소를 저장하지 않음
- 저장순서도 유지하지 않음 → 순서를 유지하려면
LinkedHashSet을 써야함 - 내부적으로 HashMap을 이용해 구현됨
- 자체적인 저장방식에 따라 순서가 결정
메서드
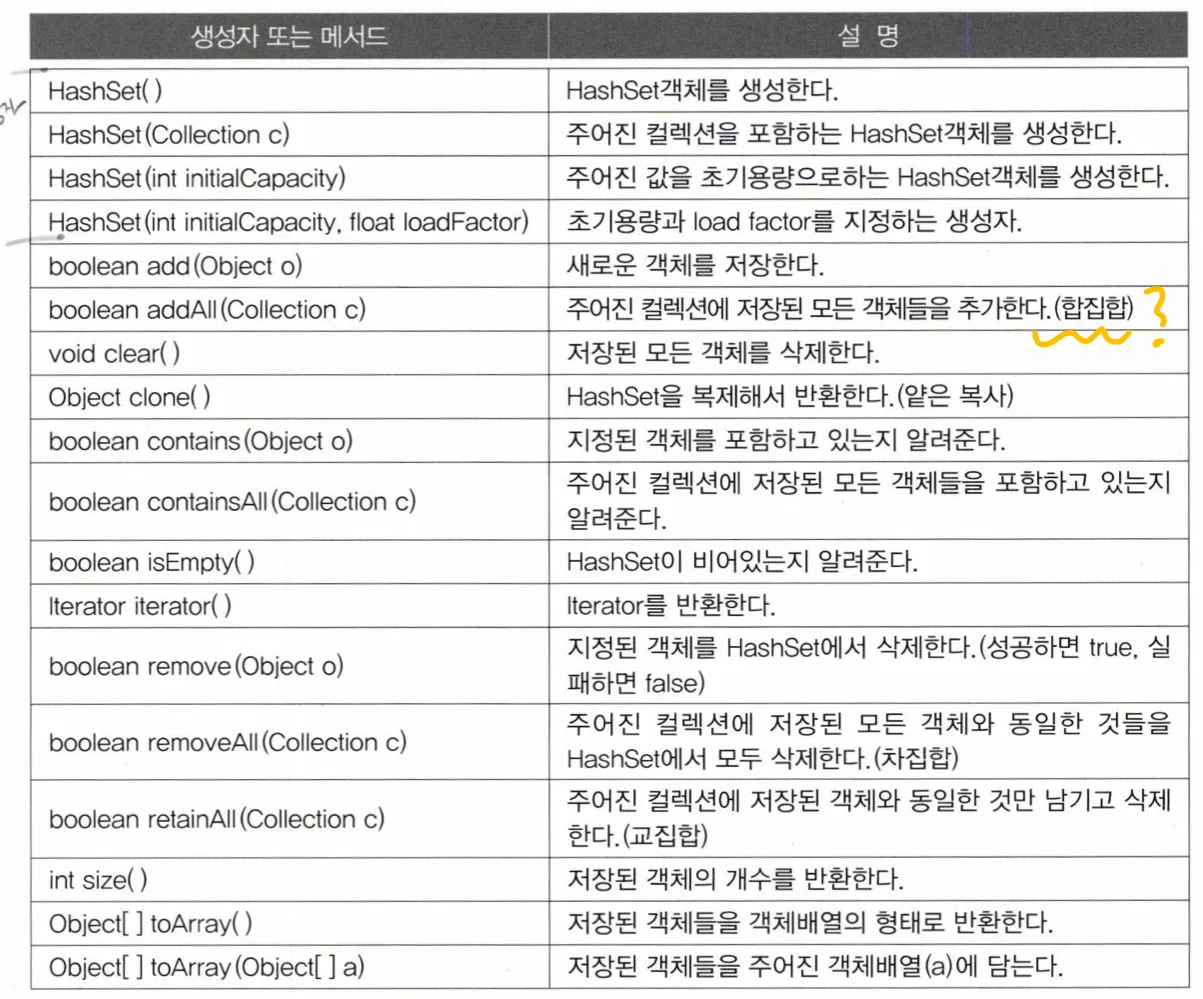
- load fator는 컬렉션 클래스에 저장공간이 가득 차기 전에 미리 용량을 확보하기 위한 것
hashCode()와equals()오버라이딩 해야하는 이유- 저장된 요소가 같은 것인지 판별하기 위해
hashCode()와equals()를 호출하기 때문
오버라이딩을 통해 작성된
hashCode()의 세가지 조건
- 동일 객체에 대해 여러번
hashCode()호출되어도 동일한 int값을 반환해야함equals()이용한 비교에서 true라면, 두 객체는 hashCode 값도 같아야함equals()이용한 비교에서 false라면, 두 객체는 hashCode 값이 같아도 괜찮지만 성능 향상을 위해 다른 int값을 반환하는 것이 좋음
- hashCode 값의 중복이 많을수록 해싱을 이용하는 컬렉션의 검색속도가 떨어짐
중요
equals() = true→hashCode() = hashCode(): hashCode() 값이 같아야함hashCode() = hashCode()→equals() != true: hashCode() 값은 관계 없음String 과 Object의 hashCode()
- String: 문자열의 내용기반으로 hashCode() 생성
- Object: 객체의 주소값을 기반으로 hashCode() 생성
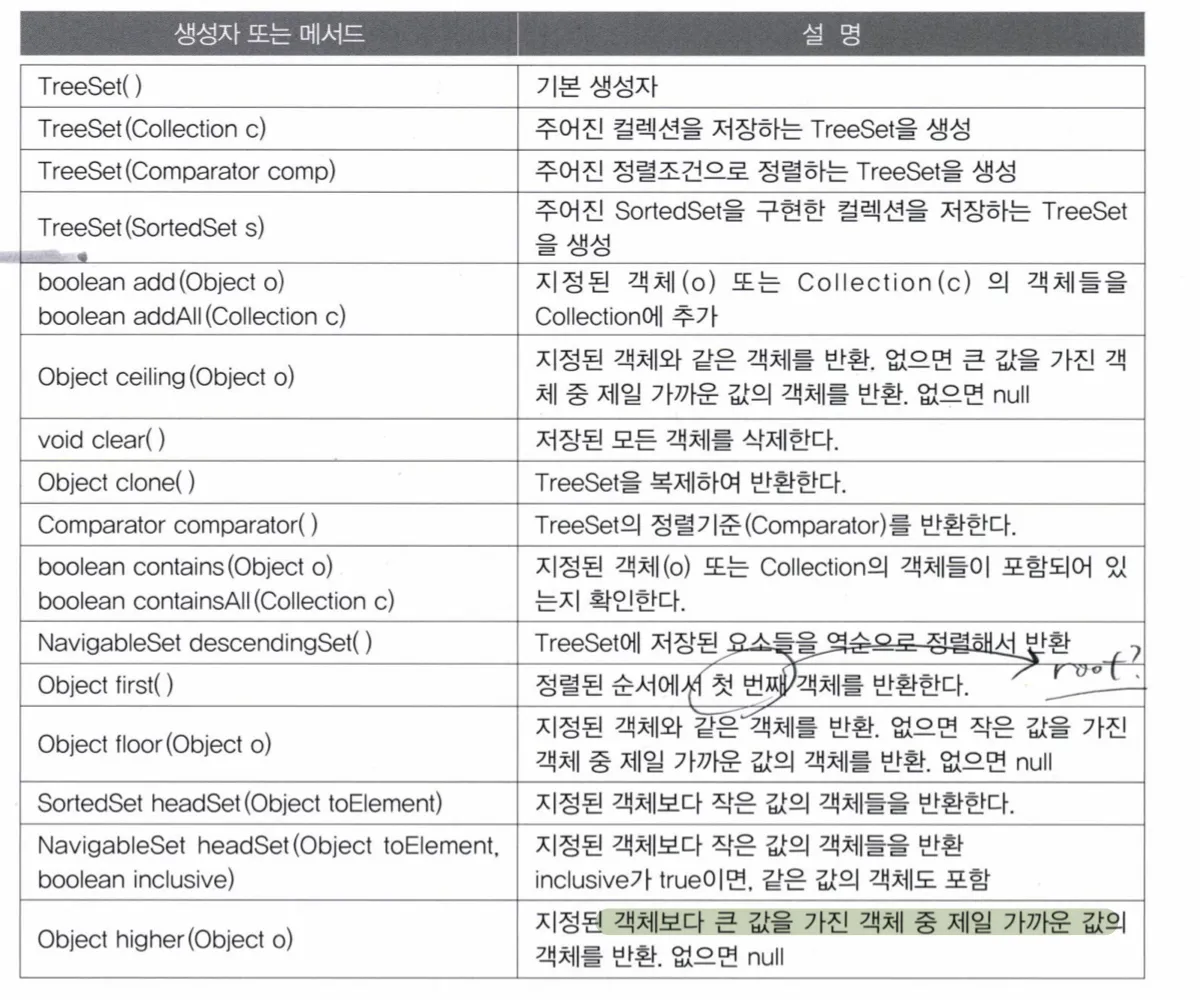
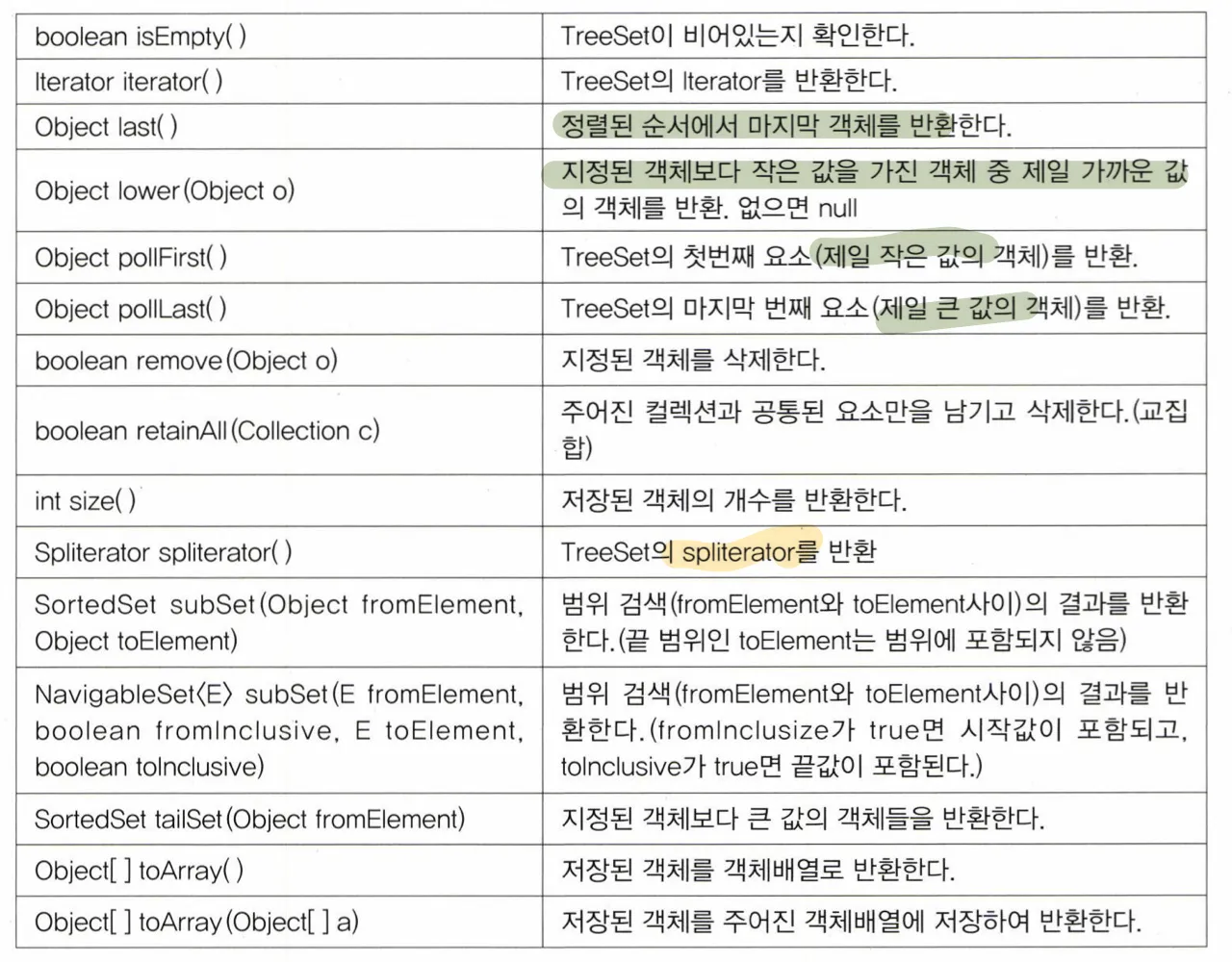
TreeSet
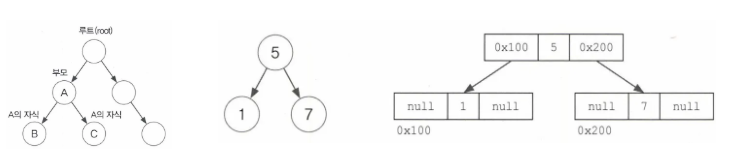
특징
- 이진 검색 트리 라는 자료구조의 형태로 데이터를 저장 → 정렬, 검색, 범위검색에 높은 성능
- 레드 - 블랙 트리로 구현되어있음
- 데이터 중복을 허용하지 않음
- 데이터의 순서를 유지하지 않음
- “루트” 노드부터 시작, 각 노드에 최대 2개의 노드를 연결
- 노드는
부모 - 자식 관계에 있음 (상대적 관계) - 왼쪽 마지막 ~ 오른쪽 마지막까지
왼쪽 → 부모 → 오른쪽순서로 읽으면 오름차순 정렬
값을 저장하는 과정
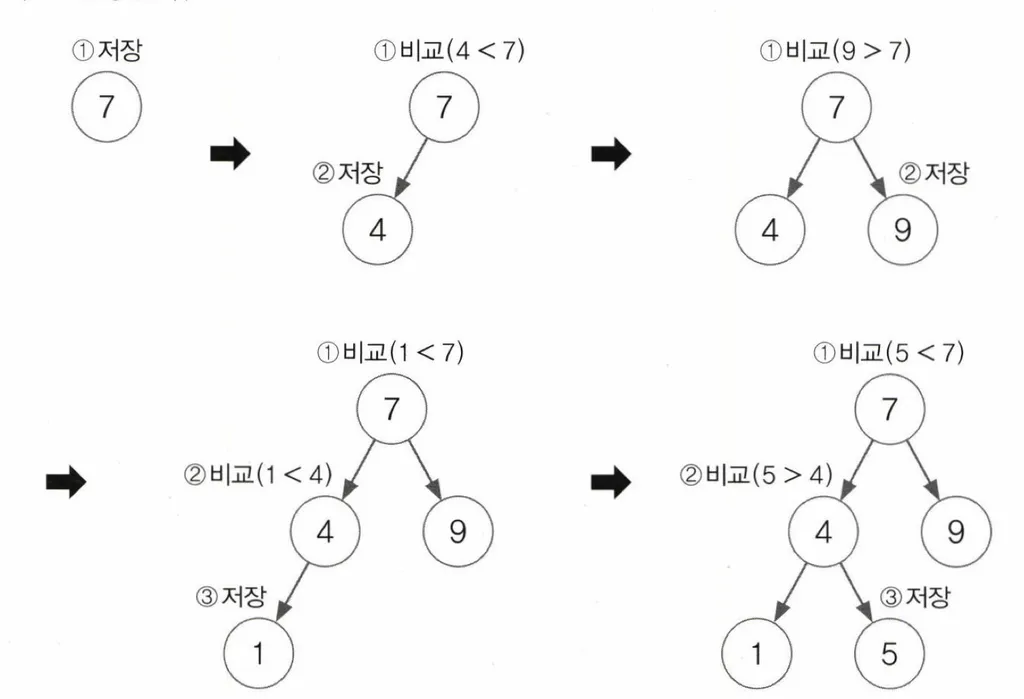
- 첫번째에 저장하는 값은 루트
- 두번째 값부터는 저장이 될 때까지 각 노드와 값을 비교해 크면 오른쪽, 작으면 왼쪽이동
- 그렇기 때문에 TreeSet에 저장되는 객체가 Comparable을 구현하던가 아니면 TreeSet에게 Comparator을 제공해 비교할 방법을 알려주어야 함
메서드
HashMap과 Hashtable
Hashtable
HashMap 이전에 사용하던 클래스, 현재는 HashMap사용을 권함
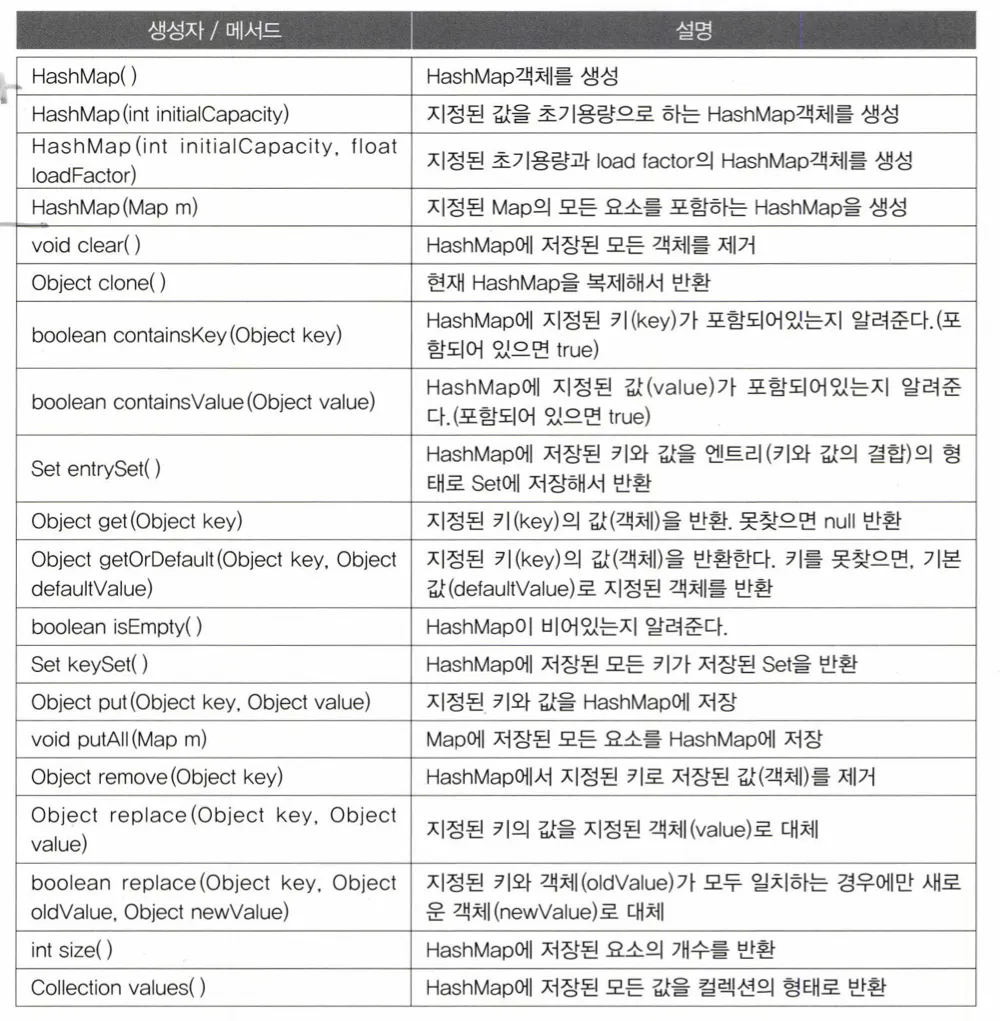
HashMap
특징
- 해싱을 사용하기 때문에 많은 양의 데이터를 검색하는데 있어서 뛰어난 성능을 보임
- key와 value를 각각의 배열이 아닌 하나의 클래스로 정의해 다루는 이유
- 객체지향적 & 데이터의 무결성적인 측면
key: 컬랙션 내에서 유일해야함 ,value: key와 달리 중복을 허용함- 만약 key가 중복되게 값을 추가하면 마지막에 추가한 값으로 덮어씌워짐
- key를
null값으로 추가할 수 있음 - 저장순서는 유지되지 않음
- 한정되지 않은 비순차적인 값들의 빈도수를 구할 수 있음
메서드
해시와 해시함수
해싱: 해시함수를 이용해 데이터를 해시테이블에 저장하고 검색하는 기법
해시함수: 데이터가 저장되어 있는 곳을 알려줌 → 다량의 데이터 중에서도 원하는 데이터를 빠르게 찾을 수 있음
- 해싱의 구조
배열과링크드 리스트의 조합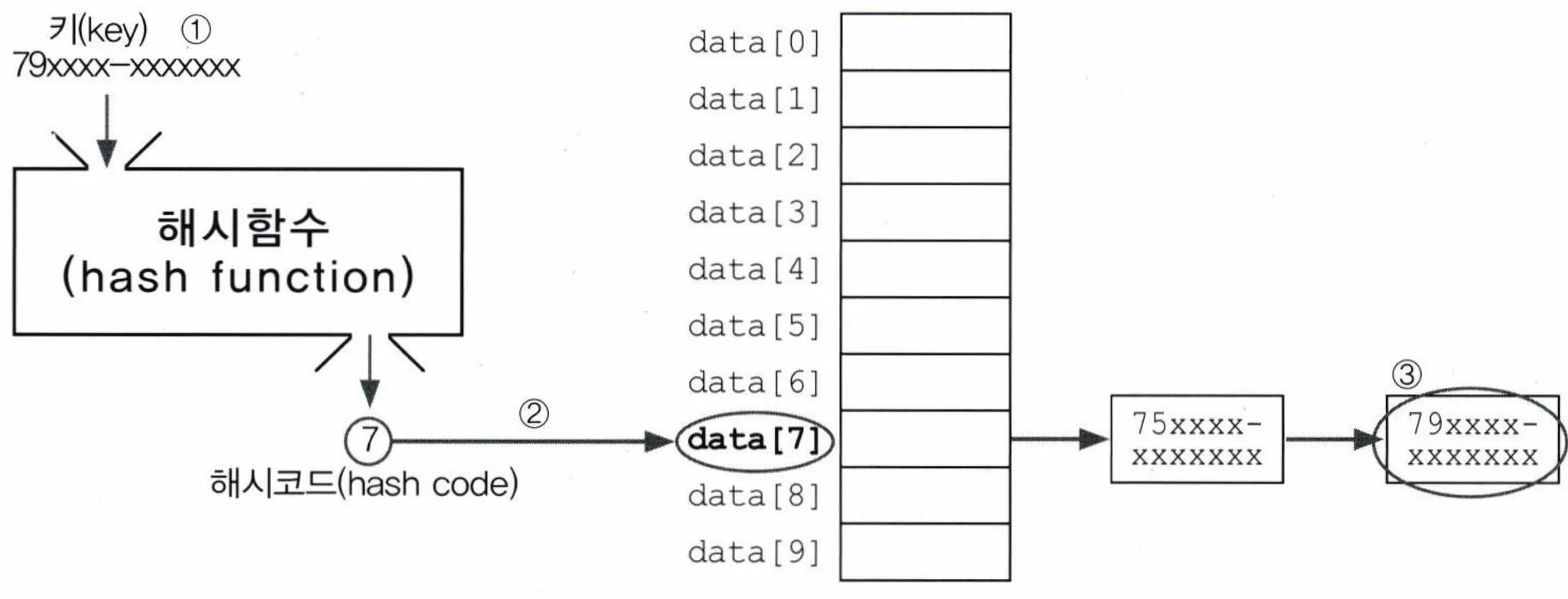
- 검색하고자 하는 값의 키로 해시함수 호출
- 계산 결과(=해시코드)로 해당 값이 저장된 링크드 리스트를 찾음
- 링크드 리스트에서 검색한 키와 일치하는 데이터를 찾음
- 배열의 각 요소에는 링크드 리스트가 저장되어있음
성능 향상 방법
- 각 배열 요소에 한개의 링크드 리스트만 있을수록
- HashMap의 크기를 적절하게 지정
- 중복된 해시코드의 반환을 최소화 → 해시함수의 알고리즘이 중요
비교시 HashCode
- equals()오버라이딩 O & hashCode()를 오버라이딩 X
- 해싱을 구현한 컬렉션 클래스 에서는 equals()의 호출결과가 true지만 해시코드가 다른 두 객체를 서로 다른 것으로 인식하고 따로 저장할 것
⇒ equals()와 hashCode() 둘 다 비교시에 같아야 같은 객체로 인식함
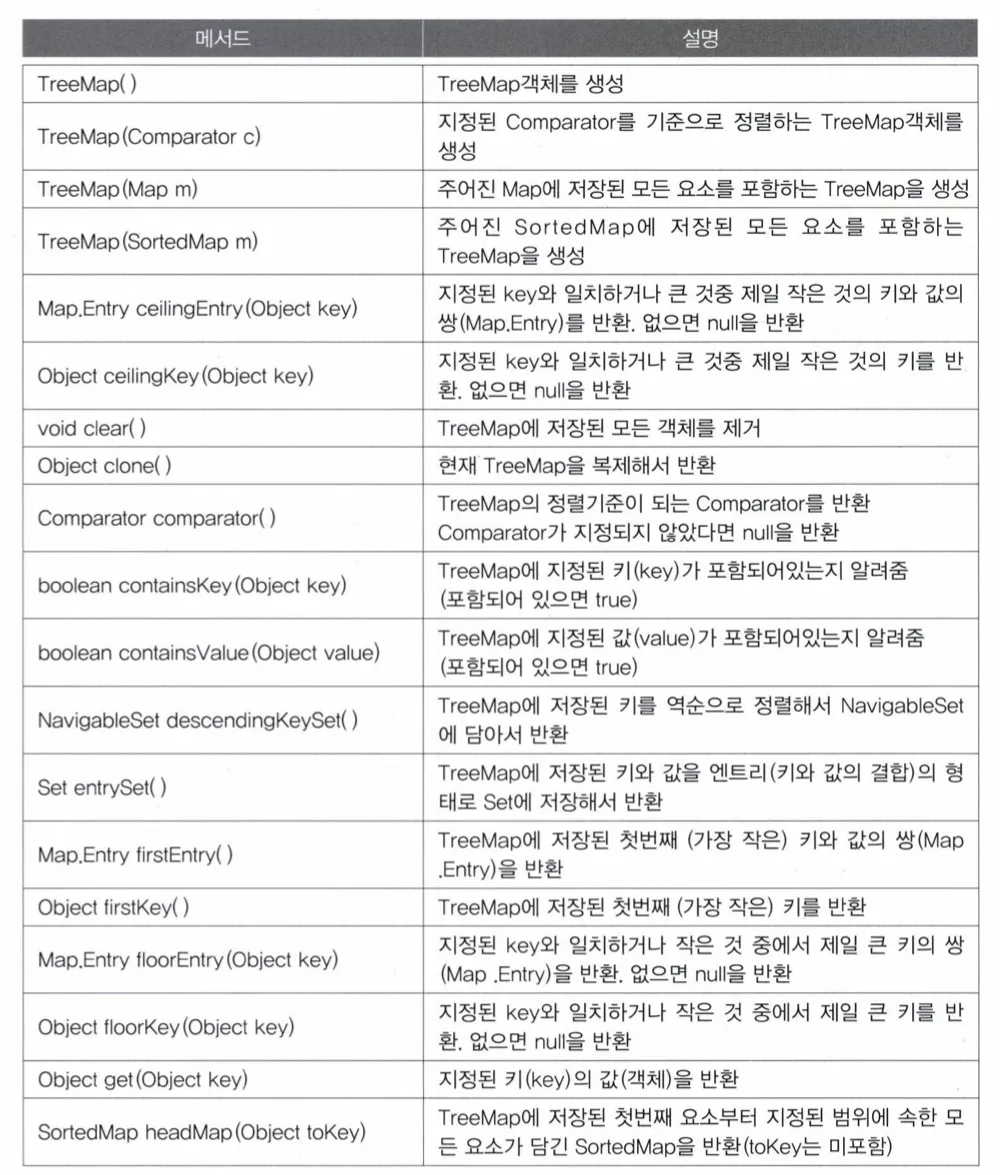
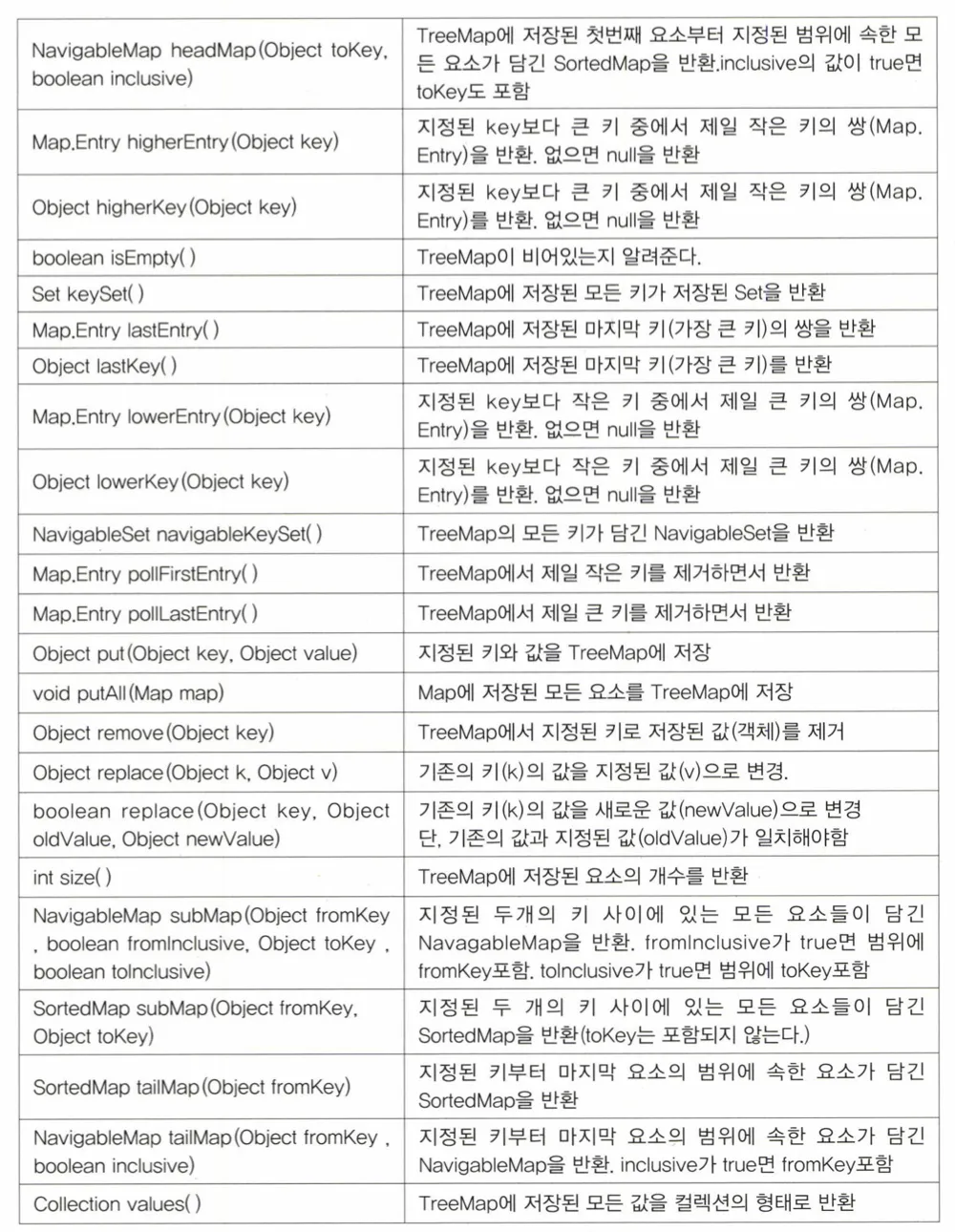
TreeMap
특징
- 이진 검색 트리의 형태로 키와 값의 쌍으로 이루어진 데이터를 저장
- 검색과 정렬에 적합한 컬렉션 클래스
- 검색 성능
- 검색: HashMap > TreeMap
- 범위검색, 정렬: TreeMap > HashMap
메서드
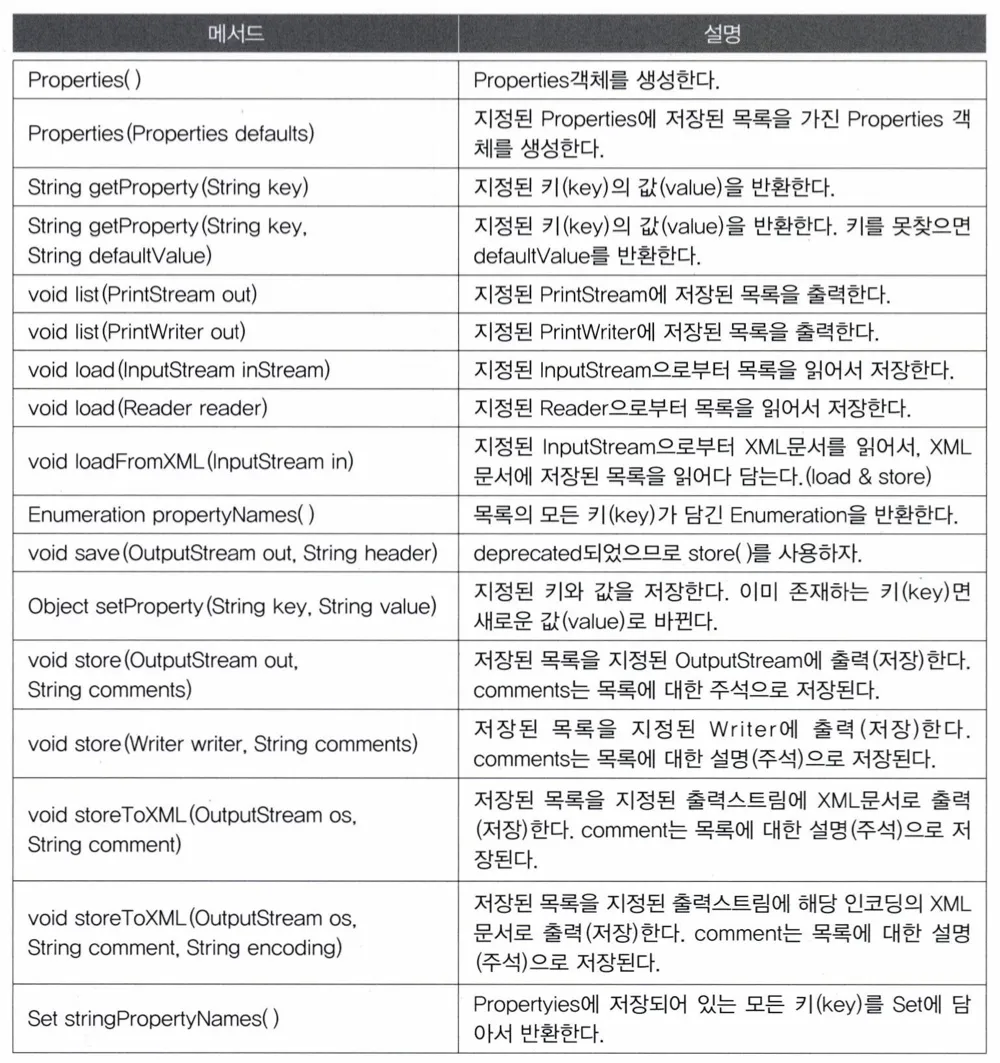
Properties
특징
- HashTable을 상속받아 구현한 것
- HashTable은 (Object, Object)의 형태, Properties (String, String)의 형태
- 주로 application 환경설정과 관련된 속성을저장하는데 활용됨
- 저장 순서를 유지하지 않음
- 외부 파일을 라인단위로 읽어
=로 연결된 형태여야함 - 주석은 맨 앞에
#으로 시작해야함
메서드
Collections
특징
- 배열의 Arrays와 같이 컬렉션과 관련된 메서드를 제공함
컬렉션의 동기화
동기화 synchronized
동기화
- 멀티쓰레드 프로그래밍: 하나의 객체를 여러 쓰레드가 쓰는 환경
- 멀티쓰레드 프로그래밍 환경에서는 일관성을 유지하기 위해 동기화가 필요함
- 동기화 : 멀티쓰레드 프로그래밍이 아닌 경우 성능을 저하시킴
- Vector와 HashTable과 같은 클래스들은 자체적으로 동기화를 처리
- 컬렉션은 자체적으로 처리하지 않고 필요시에만 java.util.Collections클래스의 동기화 메서드를 이용해 동기화 처리
변경불가 컬렉션 만들기 unmodifiable
- 저장된 데이터를 보호하기 위해 읽기전용으로 만들어야할 때가 있음
- 주로 멀티쓰레드 환경에서 여러 쓰레드가 하나의 컬렉션을 공유하다보면 데이터가 손상될 수 있기에 이를 방지할 때 사용
싱글톤 컬렉션 만들기
특징
- 단 하나의 객체만을 저장하는 컬렉션을 만들고 싶을때 사용
- 매개변수로 저장된 요소를 지정하면, 해당 요소를 저장하는 컬렉션 반환
- 반환된 컬렉션은 변경할 수 없음
메서드
singletonList(): 싱글톤 List 생성singleton(): 싱글톤 Set 생성singletonMap(): 싱글톤 Map 생성
한 종류의 객체만 저장하는 컬렉션 만들기
특징
- 컬렉션의 지정된 종류의 객체만 저장 할 수 있도록함
- 지네릭스로 간단히 처리할 수 있음
- 제공하는 이유는 호환성을 유지하기 위해
메서드
checkedCollection(): 한종류의 타입만 저장할 수 있는 Collection 생성checkedList(): 한종류의 타입만 저장할 수 있는 List 생성checkedSet(): 한종류의 타입만 저장할 수 있는 Set 생성checkedMap(): 한종류의 타입만 저장할 수 있는 Map 생성checkedQueue(): 한종류의 타입만 저장할 수 있는 Queue 생성checkedNavigableSet(): 한종류의 타입만 저장할 수 있는 NavigableSet 생성checkedSortedSet(): 한종류의 타입만 저장할 수 있는 SortedSet 생성checkedNavigableMap(): 한종류의 타입만 저장할 수 있는 NavigableMap 생성checkedSortedMap(): 한종류의 타입만 저장할 수 있는 SortedMap 생성