Data - DB Index를 사용하면 속도가 빨라지는 이유는?
DB의 인덱스는 무엇이길래, 조회 속도가 빨라지고 실제 쿼리에서는 어떻게 동작하나?
DB 쿼리 속도의 개선을 위해서, index를 사용하라는 말은 자주 들어봤다. index가 무엇인지 정도는 알고 있었지만, 이번 기회에 인덱스가 어떻게 사용되는지와 다양한 내용을 공부하며 정리해보려고 한다.
Index? 그게뭔데!
먼저 인덱스는 테이블에서 내가 자주 사용하는 컬럼들을 중심으로 서브테이블을 생성해놓는 것이라고 생각해도 좋을거같다. 테이블에는 많은 정보가 있고 기본적으로 PK를 기준으로 정렬되어있기 때문에 PK가 아닌 다른 데이터로 검색하려면 전체 데이터에서 찾을 수 밖에 없다. 그래서 검색에 자주 사용되는 컬럼을 주로 인덱스로 지정하면, 해당 컬럼에 대한 데이터를 사본으로 들고 있으며 그 컬럼을 기준으로 정렬 해놓는다. 그리고 그 컬럼에서 원하는 데이터를 찾으면, 그 데이터가 실제 테이블에서는 어느 위치인지에 대해 값을 가지고 있게 된다.
그래서 인덱스를 추가하면 속도가 빨라지지만, 데이터를 중복으로 저장하게되며 디스크의 용량을 더 차지하게 된다. 그리고 데이터의 추가, 수정이 생길때마다 인덱스에서도 처리를 해야해서 데이터 처리 속도는 느려진다. 그래서 꼭 필요한 곳에서만 사용되어야한다.
여기까지는 나를 포함해 많은 분들이 알고 있을 것이다.
도대체 어떻게 빨라질 수 있는거야?
그럼 정확히 인덱스는 어떻게 사용될까? 그리고 또 언제 사용될까?
where절을 빠르게 찾을때- 여러 인덱스가 있다면, 가장 적은 수의 행을 찾는 인덱스를 사용
- 다중 열 인덱스가 있다면, 왼쪽부터 순서에 맞는 경우
- 인덱스 - col1, col2, col3, 사용 - col1 / col1, col2 / col1, col2, col3
- 동일한 유형과 크기로 선언됐을때
- varchar(10)과 char(15)는 안되고, varchar(10)과 char(10)은 가능!
- select에 컬럼이 모두 인덱스 내에 있는 경우(=커버링 인덱스)
MIN(),MAX()를 이용하는 컬럼이 인덱스에 있을때ORDER BY와GROUP BY에 해당하는 컬럼이 인덱스에 있을때
커버링 인덱스 쿼리에서 검색한 모든 열을 포함하는 인덱스 이런 경우에는 실제 table에서 검색하지 않고, 인덱스에서만 검색하는 것으로 끝냄! 그래서 disk I/O를 절약하게 된다.
만약 index를 추가했는데, 속도가 같다면 EXPLAIN을 이용해 해당 인덱스가 사용되고 있는지 확인 할 수 있다.
Index는 어떻게 생긴거야?
MySQL을 기준으로 보자면, 크게 4가지의 인덱스 구조가 있는데 각 구조를 확인해보자.
B-TREE Index (Balanced Tree)
실제 이진 탐색 트리에서 확장된 구조로, 원래는 자식 노드를 2개밖에 가지지 못하는 트리구조에서 N개의 자식을 가질 수 있도록 했다. 이진 탐색 트리는 부모 노드를 기준으로 작은 값은 왼쪽, 큰 값은 오른쪽에 있는 자식노드 값으로 저장했는데 이와 달리 부모노드에 여러개의 데이터를 넣을 수 있고, 자식노드는 각 부모노드의 데이터를 기준으로 삼아 범위가 설정된다.
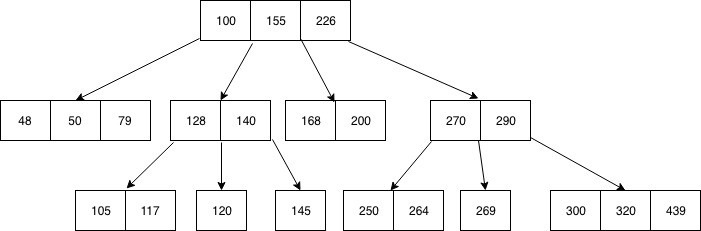 b-tree 구조 시각화, 출처 : [MySQL] B-Tree로 인덱스(Index)에 대해 쉽고 완벽하게 이해하기
b-tree 구조 시각화, 출처 : [MySQL] B-Tree로 인덱스(Index)에 대해 쉽고 완벽하게 이해하기
이와같이 부모가 (N-1)의 데이터를 가지면, 그 데이터를 기준으로 N개의 자식 노드가 생기게된다. 그리고 각 자식노드도 같은 구조의 서브트리를 갖게된다.
- 특징
- 보통 index라고 했을 때 가장 많이 사용되고, index의 기본 구조로 설정되어있다.
- 항상 오름차순으로 정렬이 된다.
- 이진 탐색을 이용할 수 있기에
O(log N)의 속도로 탐색 가능해 검색 속도가 빠르다.- 범위 검색(
=,<,<=,>,>=,BETWEEN)에 적절하다. 단, 상수 문자열(=’검색어’)의 경우 와일드카드(%)가 문자열 시작에 포함된다면 사용되지 않는다.- 단점은 데이터의 삽입/삭제시 균형을 유지해야해서 비용이 발생하게된다. 삽입시에 노드의 데이터가 가득차면 분할을 발생시키고, 삭제시에는 병합하거나 재배열을 통해 트리의 균형을 유지한다.
- 항상 오름차순으로 정렬이 된다.
B-tree에 더 궁금하거나 자세히 알고싶다면, 공부하면서 찾은 좋은 자료를 소개한다.
- 데이터베이스 인덱스는 왜 ‘B-Tree’를 선택하였는가
- 왜 index에서 B-tree를 구조를 기본으로 사용하게 되었는지에 대해 정리한 글로, 다양한 자료구조까지 같이 설명하고 있다.
- (1부) B tree의 개념과 특징, 데이터 삽입이 어떻게 동작하는지를 설명합니다! (DB 인덱스과 관련있는 자료 구조)
- B-tree에 대해 다양한 시각 자료를 통해 쉽게 설명하고 있다.
Hash Index
Hash는 이름에서 유추하듯 해시함수를 이용한 구조로, HashMap과 같은 구조로 key값을 hash 함수결과에 따라 결정된다. 그래서 HashMap과 같이 O(1)매우 빠른 검색속를 자랑한다. 그런데 기본인덱스로 설정되지 않은 이유는 뭘까? hash index는 = 연산에서만 사용된다는 점이다. 우리는 DB에서 검색시 등가비교(=)보다 범위 검색(=,<, <=,>, >=,BETWEEN, LIKE)을 더 자주 이용하는데, hash index는 해시 결과를 기반으로 하는 인덱스라 범위 검색이 불가능하다.
- 특징
- 등가비교에서는
O(1)의 매우 빠른 속도로 조회된다. MySQL의 MEMORY 엔진에서만 지원, InnoDB에서는 Hash Index를 자동으로 생성하는 Adaptive Hash Index를 사용한다.- 범위 검색, 정렬(ORDER BY), 그룹화(GROUP BY)가 필요한 경우에는 사용될 수 없다.
- 해시 충돌 발생시에는 Linked List 또는 Open Addressing 방식이 사용된다.
- 범위 검색, 정렬(ORDER BY), 그룹화(GROUP BY)가 필요한 경우에는 사용될 수 없다.
- 어디에 사용되면 좋을까?
- Key-Value 기반의 빠른 조회가 필요한 경우(session_id, API token 같은 고유한 값 조회시)
- 자주 조회되지만 업데이트가 거의 없는 데이터
Inverted Index
문장을 단어(토큰) 단위로 분해하여, 각 단어가 어떤 문서에 포함되는지를 색인하는 방식이다. elasticsearch에서도 text타입에 대해서는 inverted index가 생성되는데 이와 같다. 토큰이라고 하면, MySQL is fast라는 문장이 있을 때 특정 기준(ex. 공백)으로 잘라낸 MySQL, is, fast와 같은 것을 말한다. 텍스트 필드의 모든 단어를 자동으로 색인하고, 역색인 구조를 생성하여 빠른 검색을 가능하게 한다.
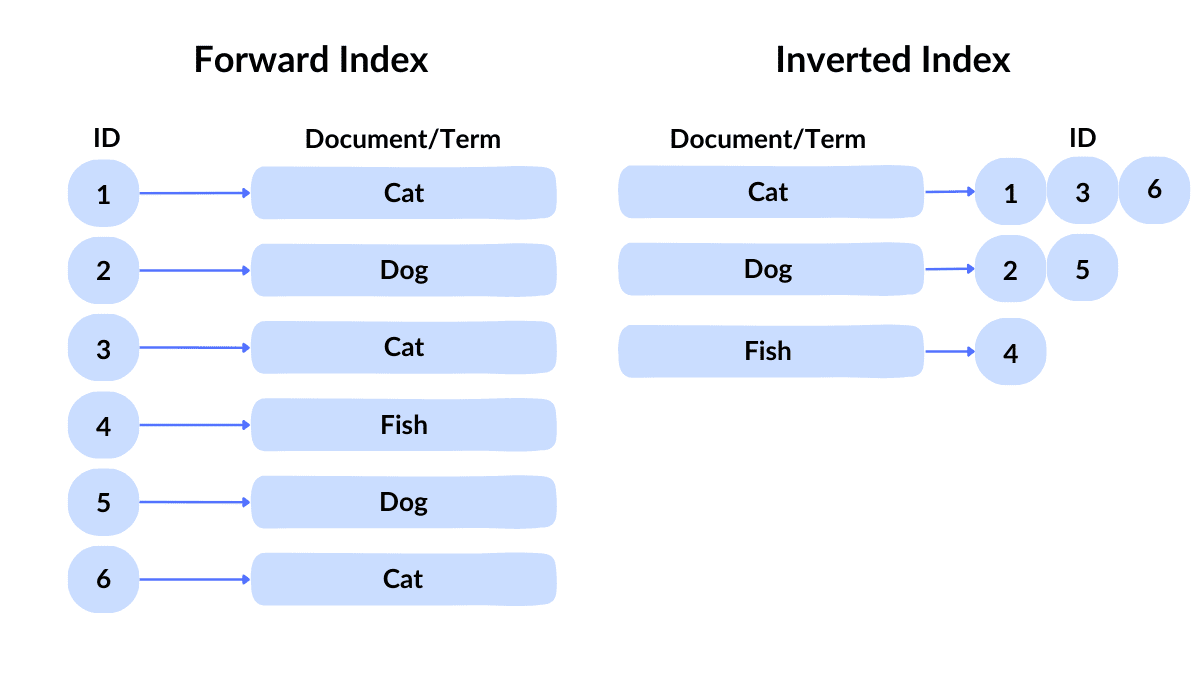 inverted-index 구조 시각화
inverted-index 구조 시각화
왼쪽이 기존 방식이였다면, 오른쪽이 inverted indexd에 해당된다.
- 특징
- 자연어 검색에 최적화 되어있어 LIKE ‘%검색어%’보다 훨씬 빠르다.
- 대신 데이터의 삽입/삭제 시마다 역색인에 대한 비용이 발생하게 된다. 삽입 - 데이터를 전부 토큰화 -> (이 데이터에만 있는 토큰이라면 역색인하는 단어에 추가하고) -> 데이터의 key 값을 저장한다. 삭제 - 해당 데이터와 연결된 모든 단어를 역색인에서 제거한다.
- 정확한 값 검색이나 숫자나 날짜필드에 대한 검색에서는 권장되지 않는다.
- 대신 데이터의 삽입/삭제 시마다 역색인에 대한 비용이 발생하게 된다. 삽입 - 데이터를 전부 토큰화 -> (이 데이터에만 있는 토큰이라면 역색인하는 단어에 추가하고) -> 데이터의 key 값을 저장한다. 삭제 - 해당 데이터와 연결된 모든 단어를 역색인에서 제거한다.
- 어디에 사용되면 좋을까?
- 검색어가 포함된 문서를 찾는 경우(사용자가 입력한 검색어를 포함하는 문서를 빠르게 찾을 수 있음)
- 자연어 처리(NLP) 기반 검색
R-Tree Index
R-tree는 다차원 데이터를 저장하는 트리 구조로, B-Tree처럼 계층적 구조를 가진다. 대신 저장되는 데이터가 B-TREE는 1차원 데이터를 R-TREE는 다차원(2D, 3D)데이터를 저장한다는 차이가 있다. 다차원 데이터란 여러 개의 값(좌표)로 표현되는 데이터로 예시로는 위치 정보, 3D 모델, 색상 정보 등이 있다. MySQL은 공간 정보의 저장 및 검색을 위해 POINT, LINE, POLYGON, GEOMETRY라는 데이터 타입을 제공한다.
공간 데이터 타입 MySQL에는 OpenGIS 클래스에 해당하는 공간 데이터 유형이 있는데 아래와 같다.
공간 데이터 타입, 출처 : [Real MySQL 8.0] R-Tree와 전문 검색 인덱스
- GEOMETRY
- 모든 공간 데이터를 위한 일반적인 공간 데이터 타입입니다.  POINT
- X, Y 좌표를 나타내는 0차원 지리 공간 데이터입니다. LINESTRING
- 선분의 집합을 나타내는 1차원 지리 공간 데이터입니다. POLYGON
- 면을 나타내는 2차원 지리 공간 데이터입니다.
이 외에도 MULTIPOINT, MULTILINESTRING, MULTIPOLYGON, GEOMETRYCOLLECTION가 있는데, 이는 공식 문서를 참고하자.
- 특징
- B-tree 구조로 이진 탐색을 통해 조회된다.
- B-tree는 1차원 데이터로 비교가 쉬웠는데, R-tree는 다차원 데이터로 Bounding Box를 비교하는 방식을 이용한다. 부모 노드는 자식 노드들의 Bounding Box를 포함하는 구조를 가진다.
- 검색시에는
ST_Contains(A, B),ST_Within(A, B),ST_Intersects(A, B),ST_Distance(A, B)등을 이용해 범위 검색을 하게 된다.- 속도의 향상을 위해서는 Bounding Box 크기와 겹치는 영역 최소화하는 것과 트리가 너무 한쪽으로 치우치지 않도록 유지하게 한다.
- B-tree는 1차원 데이터로 비교가 쉬웠는데, R-tree는 다차원 데이터로 Bounding Box를 비교하는 방식을 이용한다. 부모 노드는 자식 노드들의 Bounding Box를 포함하는 구조를 가진다.
- Bounding Box
- 다차원 공간 데이터를 감싸는 최소한의 직사각형이다.
Bounding Box, 출처 : [Real MySQL 8.0] R-Tree와 전문 검색 인덱스
- 어디에 사용되면 좋을까?
- 위치 기반 검색과 지리 정보 시스템(GIS)에 적합
- 지도 데이터, 경로 탐색, 공간 분석, 이미지 검색 등에서 자주 활용