ElasticSearch Essential - 03 동작 이해하기
색인, 검색의 기본적인 동작 원리 이해
색인 과정 이해하기
색인 과정
- 색인(indexing)
- 문서를 분석하고 저장하는 과정이이다.
- elasticsearch에 어떤 문서를 입력시 이 문서를 분석하고, 스토리지에 저장하는 일련의 모든 과정을 의미한다.
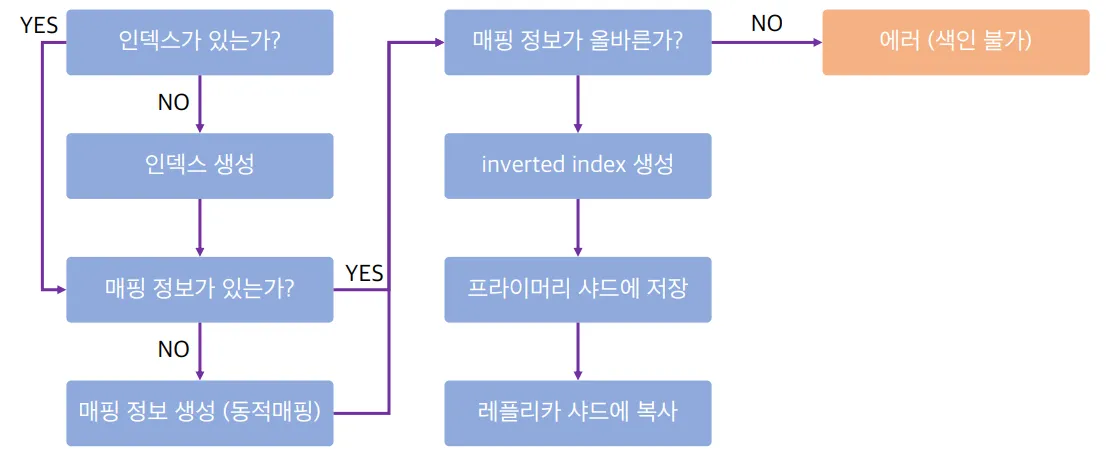 전체의 색인 과정
전체의 색인 과정
- 인덱스가 있는가?
- 없으면, 인덱스를 생성
- 매핑 정보가 있는가?
- 없으면, 동적 매핑을 통해 매핑을 통해 생성함
- 매핑 정보가 올바른가?
- 올바르지 않다면, 에러 발생
inverted index생성- 프라이머리 샤드에 저장
- 레플리카 샤드에 복사
- inverted Index 생성
- 가장 리소스를 많이 사용하는 작업으로, 검색과도 밀접한 관련이 있다.
예시를 통한 색인 과정
예시1: 클러스터의 이점을 살리지 못하는 예시
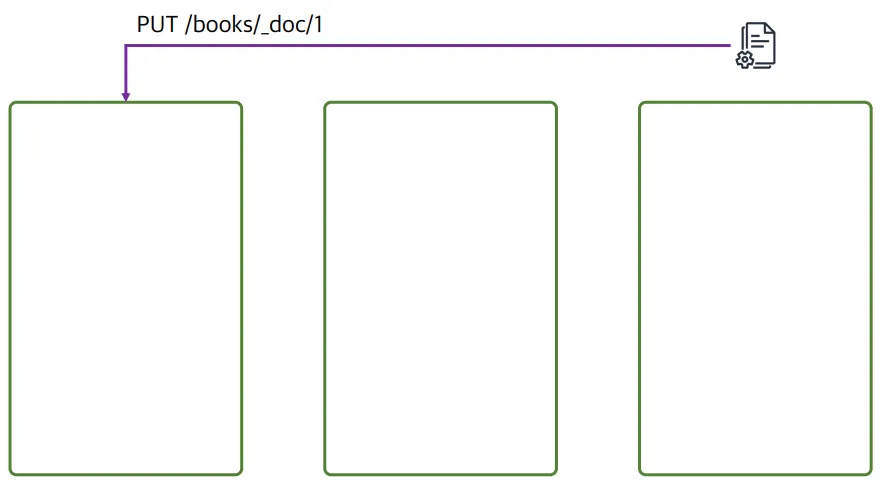 3개의 녹색 상자는 데이터 노드를 의미
3개의 녹색 상자는 데이터 노드를 의미
- 첫번쨰 데이터가 들어왔을 때
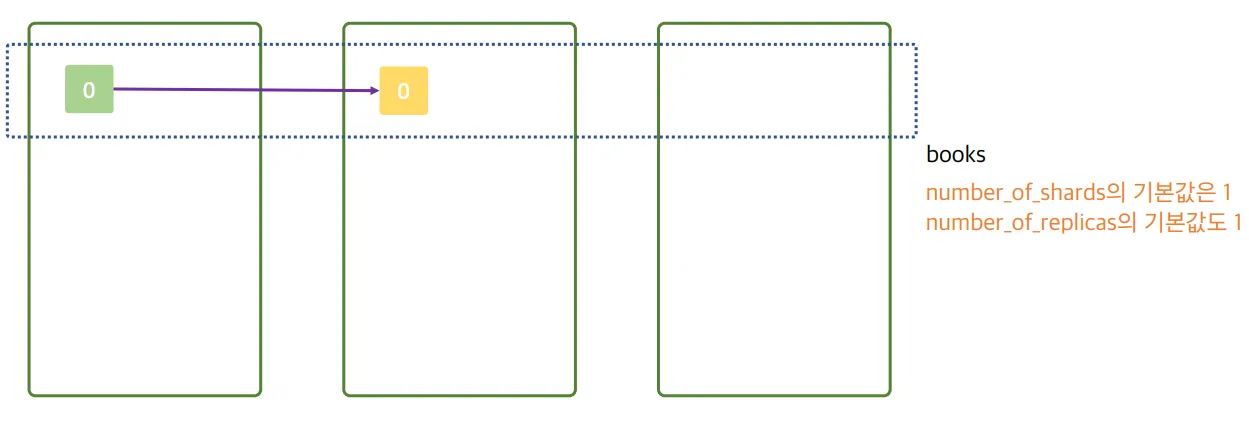
- 인덱스가 없어서 books라는 인덱스가 생성됨
- 1번쨰 데이터 노드의 프라이머리 샤드, 2번쨰 데이터 노드에 레플리카 샤드가 만들어짐
number_of_shards의 기본값은 1,number_of_replicas의 기본값도 1
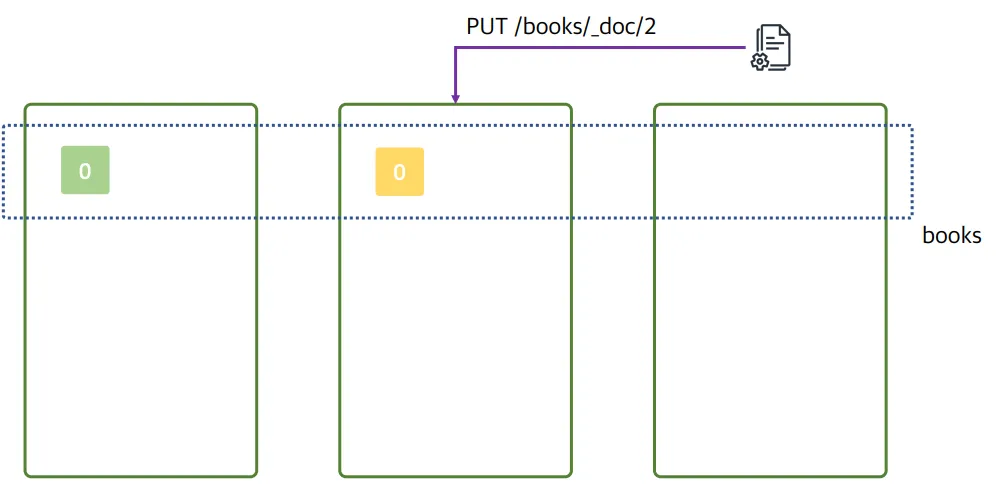 2번 데이터가 들어온 상황
2번 데이터가 들어온 상황
- 2번 데이터의 PUT 요청이 2번 노드에게 들어옴 elasticsearch는 클러스터로 구성되어있기 때문에, 어떤 노드로 들어오더라도 동일한 응답을 보장함
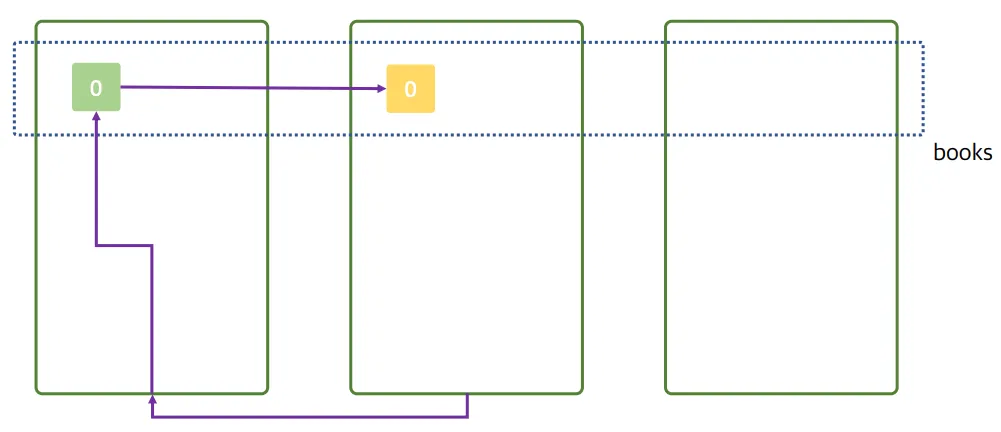 2번 노드가 1번 노드에게 요청을 전달함
2번 노드가 1번 노드에게 요청을 전달함
- 2번 노드는 저 문서를 저장하기 위한 프라이머리 샤드를 가지고 있지 않아, 자신이 받은 요청을 1번 노드에게 전달함
- 1번 노드는 요청을 받아 프라이머리에 저장을 하고, 레플리카 샤드에 복사됨
- 지금까지의 과정을 봤을 때, 3번 노드는 아무런 일을 하지 않고 있음
- 3번 노드는 아무런 샤드가 없기 때문
- 데이터 노드가 3개이지만, 색인에 있어서는 사실상 1개만 있는 것과 같음
- 이 경우가 클러스터로서의 이점을 전혀 살리지 못하는 이유
- 클러스터로 구성은 되어있지만(=노드는 3개이지만), 적절한 수의 샤드를 설정하지 않아 성능이 좋지 않음 ⇒ 적절한 수의 샤드 개수를 설정하는 것이 성능에 큰 영향을 미침
예시2: 클러스터의 이점을 잘 살린 예시
예시1과 모든 상황이 동일한데, 인덱스 템플릿을 적용해 number_of_shards= 3, number_of_replicas=1 으로 설정한 상황
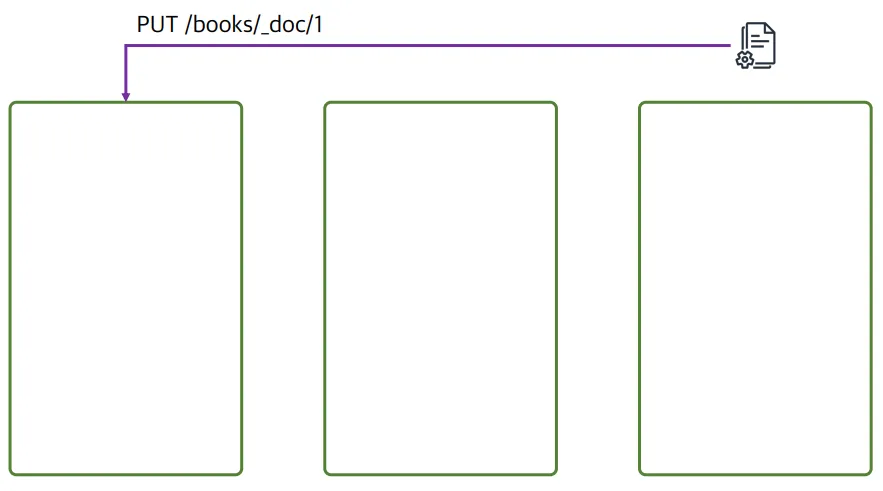 1번 데이터가 들어온 상황
1번 데이터가 들어온 상황
- index가 없었기 때문에 생성됨
- 정의된 인덱스 템플릿에 따라 3개의 노드가 생성될 때, 프라이머리 샤드 3개, 레플리카 샤드 3개가 생성됨(연두: 프라이머리, 노랑: 레플리카)
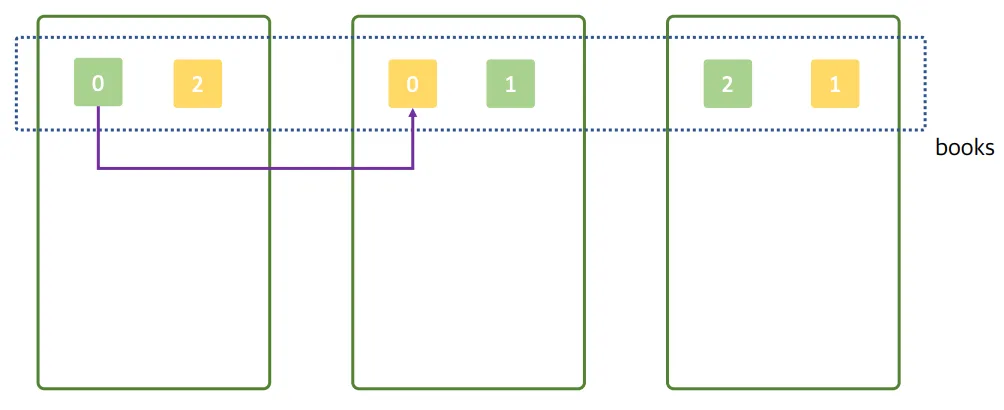 1번 데이터가 들어온 상황
1번 데이터가 들어온 상황
- 1번 데이터가 들어옴
- 0번 프라이머리 샤드에 데이터가 저장
- 0번 레플리카 샤드에 복사됨
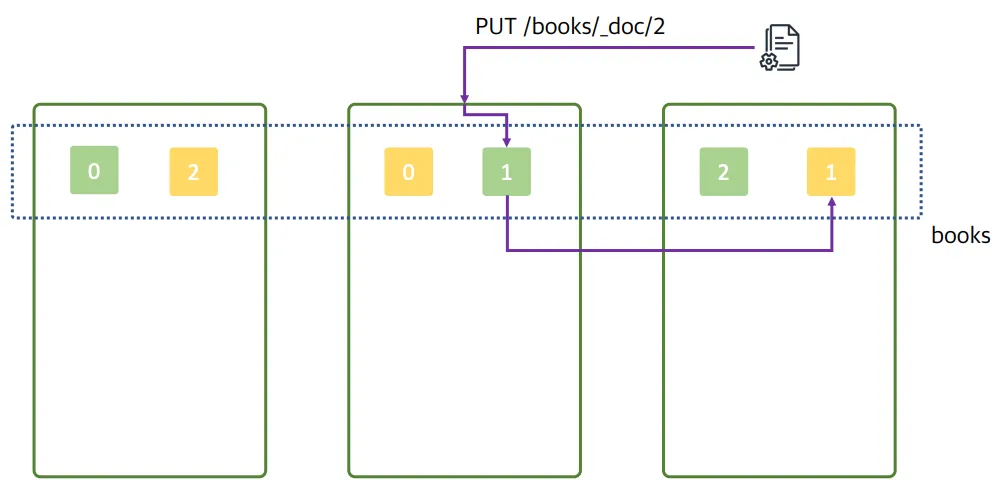 2번데이터의 PUT 요청이 2번 노드에게 들어옴
2번데이터의 PUT 요청이 2번 노드에게 들어옴
- 2번 데이터가 들어옴
- 1번 프라이머리 샤드에 데이터가 저장
- 1번 레플리카 샤드에 복사됨
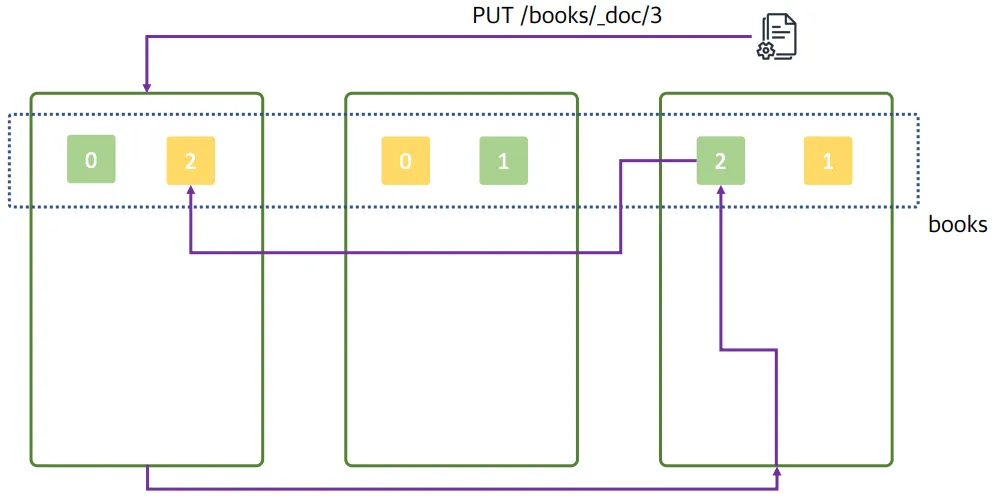 3번 데이터가 1번 노드에 들어옴
3번 데이터가 1번 노드에 들어옴
- 3번 데이터가 들어옴 (클러스터의 이점을 살려보는 가정을 하기 위해 0번 노드에 들어갔다고 가정)
- 0번 노드가 2번 노드에게 전달
- 2번 프라이머리 샤드가 저장
- 2번 레플리카 샤드에 복사됨
⇒ 데이터 노드가 3개가 있고, 3개 모두 색인 과정에 참여함
예시3: 샤드가 고르게 분배되지 않은 상황
예시2와 상황이 동일한데, 여기서 데이터 노드가 1개 더 추가된 상황
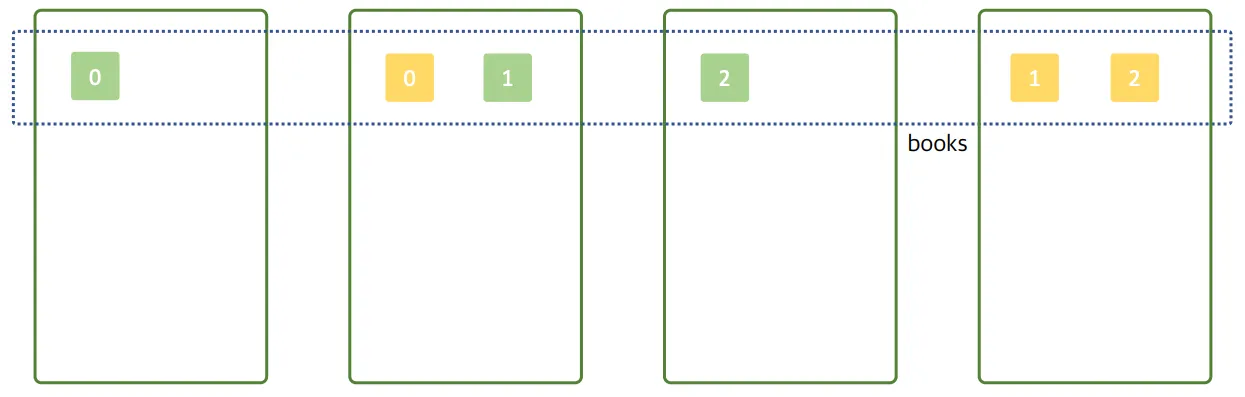
노드가 4개, 프라이머리 샤드 3개, 레플리카 샤드3개로 노드가 늘어나도 실제 데이터를 저장하는 샤드의 개수가 늘어나지 않음 -> 용량 불균형 문제: 샤드당 10기가씩이라고 했을 때, 노드별로 용량이 다름
- 운영시 어려움: 데이터 노드를 늘렸는데 용량이 고르게 분포되지 않는 이유?
- 샤드가 고르게 분배되지 않았기 때문
적절한 샤드의 수
참고 자료: elasticsearch 공식문서 - 사이징 샤드 사이즈
- 방법
- 현재 상황에 맞는 샤드 배치 계획을 처음부터 완벽하게 세울 수 없음을 알고, 계속 테스트하고 클러스터를 살펴보며 배치 계획을 완성시켜 나아가야한다.
예시: 하루에 100g의 로그를 30일간 저장하는 클러스터
- 초기 계산
- 필요한 저장 공간 계산 : 100g. * 2(레플리카) * 30일 = 6,000g
- 인덱스별 샤드의 최대 크기를 10g로 설정시, 인덱스 별 프라이머리 샤드의 개수는 10개
- 데이터 노드의 개수를 10개로 설정시, 데이터 노드당 가져야 할 디스크의 크기는 600g, 600은 최소 용량이니, 데이터 노드의 장애를 대비해 700g로 설정
- 이후 사용 패턴이나 성능 문제등에 맞춰서 샤드의 수를 늘리거나 데이터 노드를 스케일 아웃/업하면서 최적의 수치를 찾아가도록 한다.
- CPU가 남는다면 노드당 프라이머리 샤드의 개수를 1개에서 2개로 늘린다.
- 색인 성능에 문제가 있다면, 클러스터의 이점을 살리고 있는지를 확인한다.
검색 과정 이해하기
검색 과정
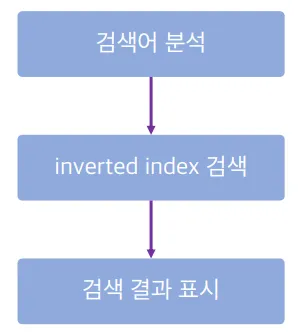
- 검색어 분석:
analyzer를 적용해 토근을 만들어냄 - inverted index 검색: 분석한 검색어들(=생성된 토큰)을
inverted index내에서 검색 - 검색 결과 표시
inverted index
- inverted index
- 문자열을 분석한 결과를 저장하고 있는 구조체이다.
예제
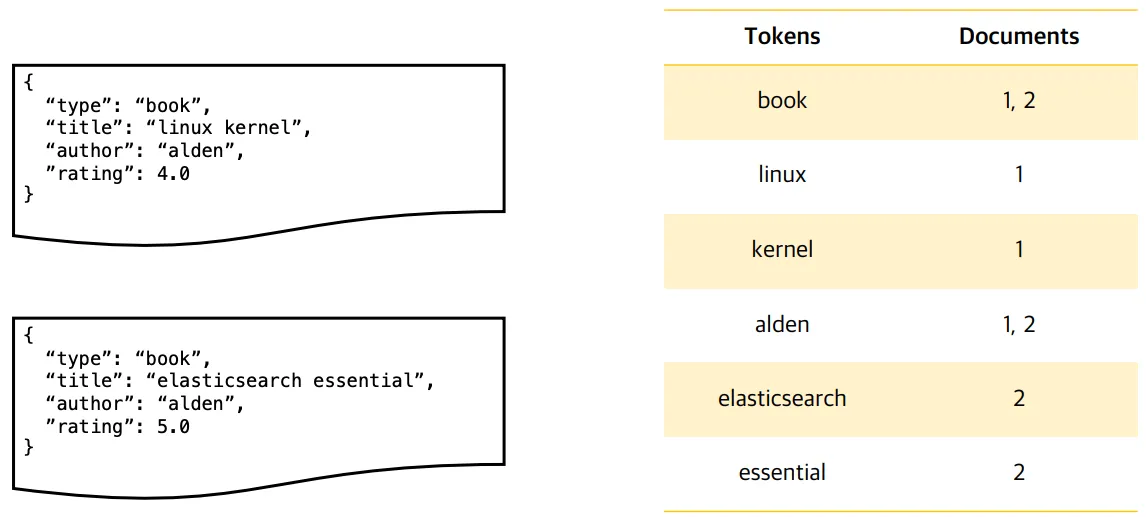 왼쪽에 있는 2개의 문서를 분석한 후 만들어진 결과(=오른쪽)
왼쪽에 있는 2개의 문서를 분석한 후 만들어진 결과(=오른쪽)
분석 결과
- Tokens: 문자를 구성하고 있는 단어들을 분석기를 통해 생성해낸 것
- documents:
tokens이 어떤 문서에 있는지에 대한document id
애널라이저(Analyzer)
- 애널라이저(Analyzer)
- 문자열을 분석해서 inverted index 구성을 위한 토큰을 만들어 내는 과정이다.
- 여러개의 애널라이저가 있고, 자신만의 애널라이저를 만들 수 있다.

- character filter ex) 특수문자 제거
- tokenizer ex) 공백을 기준으로 나눔
- token filter ex) 대소문자를 모두 소문자로 만듬
테스트 방법
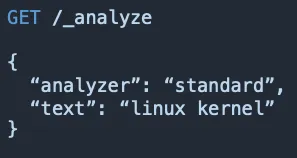
/_analyze에 GET 방식으로 분석할 애널라이저 이름과 텍스르를 보내 결과를 조회 → 검색이 잘 안된다면, 내가 원하는 대로 토크나이징이 잘 되고있는지를 확인해야함
검색 과정에서의 샤드
검색 요청은 프라이머리 샤드와 레플리카 샤드 모두 처리할 수 있다.
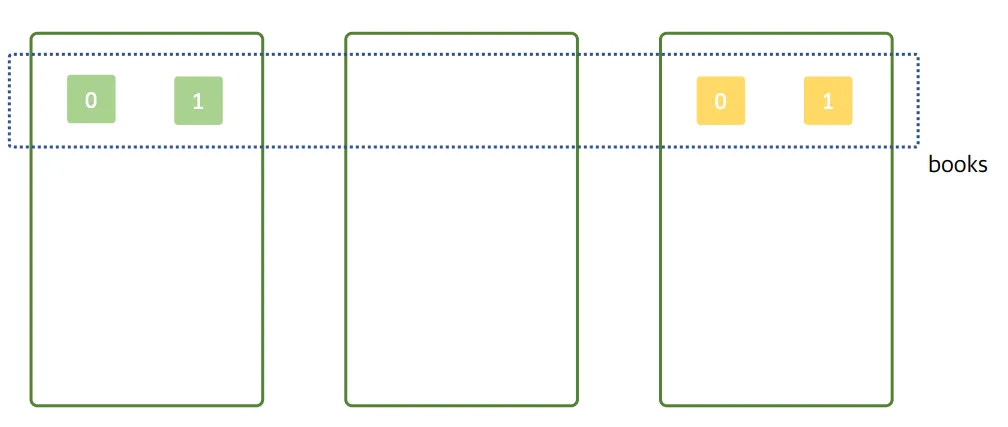 샤드의 분배가 적절하지 못한 예시
샤드의 분배가 적절하지 못한 예시
2번째 노드는 검색 과정에서 아예 사용되지 못하고 있음 → 클러스터로서의 이점을 활용 못하고 있음
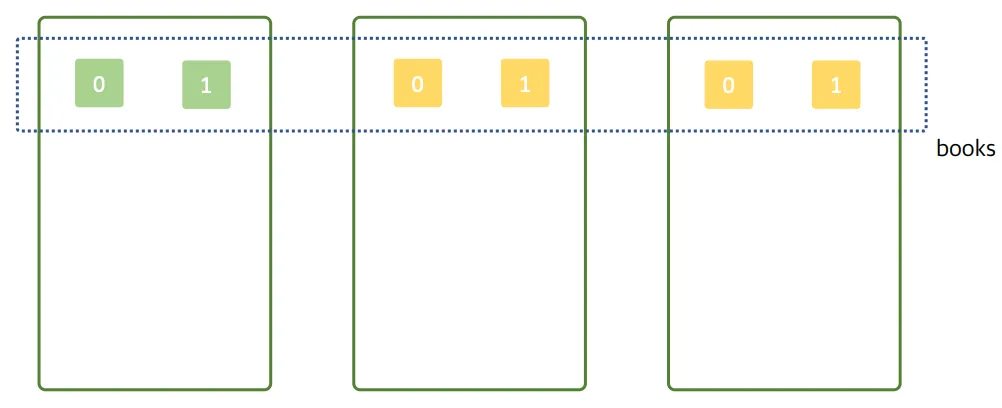 샤드의 분배가 적절한 예시
샤드의 분배가 적절한 예시
위의 예시에서 프라이머리 샤드를 늘리고 싶지 않다면, 레플리카 샤드만 늘림으로써 검색성능을 개선 (= 색인 성능은 충분하고, 검색 성능만 개선하고싶다면)
→ 운영중에 프라이머리 샤드의 수는 변경할 수 없지만, 레플리카 샤드의 수는 변경할 수 있다.자세히 ⇒ 검색 성능을 더 높이고싶다면, 노드와 함께 레플리카 샤드를 함께 늘려야함!
text vs keyword
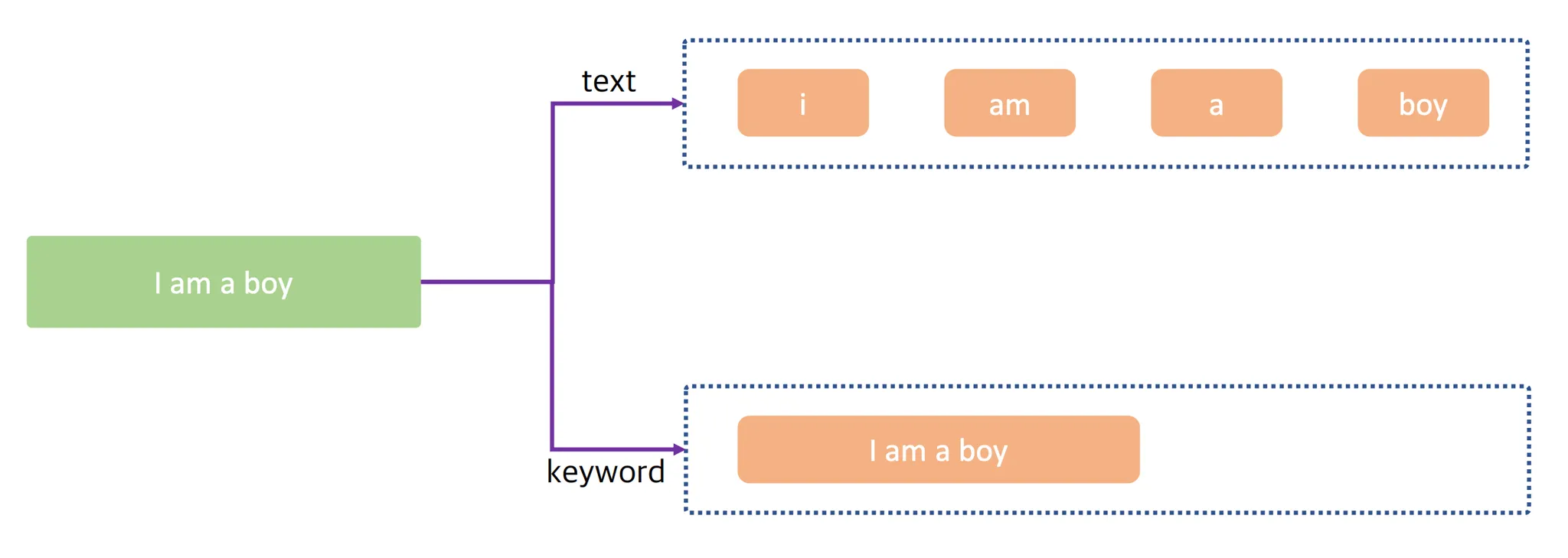 애널라이저에서 토큰화 된 text와 keyword의 차이
애널라이저에서 토큰화 된 text와 keyword의 차이
둘 다 문자열을 나타내기 위한 타입이지만, 차이점도 존재한다.
- text
- 전문 검색(full-text search)을 위해 토큰이 생성됨
- 예시에서 각 토큰(
i/am/a/boy) 중 하나가 입력되어도 원문이 검색됨- 전문 검색(full-text search)가 필요한 필드 ex) 주소, 이름, 상세 물품 정보 등
- 예시에서 각 토큰(
- keyword
- 정확하게 일치하는지 검색(exact matching) 을 위해 토큰이 생성됨
- 예시에서 토큰 자체가
i am a boy이기 떄문에, 똑같이 입력해야지만 검색됨- text 타입보다 색인 속도가 더 빠름(문자열을 나누거나 하는 작업이 없기 때문)
- 검색시 모든 글자를 입력하는 필드 ex) 성별, 물품 카테고리 등
- 예시에서 토큰 자체가
→ 토큰이 어떻게 생성되느냐, 용도가 어떻게 되느냐에 따라 다르게 사용할 수 있음 → 문자열 필드가 동적 매핑되면 text와 keyword 두 개의 필드가 만들어짐 ⇒ 문자열 특성에 따라 text와 keyword를 정적 매핑하면 성능에 도움이 됨