ElasticSearch Essential - 04 모니터링 하기
cat API를 이용해 모니터링 하는 방법을 살펴보고, 주요 모니터링 지표를 살펴보자.
ElasticSearch Essential - 04 모니터링 하기
cat API 활용하기
cat API(Compact and Aligned Text APIs)란?
- cat API
- 클러스터의 정보를 사람이 읽기 편한 형태로 출력하기 위한 용도로 만들어진 API다.
- UI 기반의 모니터링 시스템보다 빠르게 확인할 수 있다는 장점이 있다.
- 8.0 버전을 기준으로 20개 이상을 지원하고 있다. (본 내용에는 4개만 정의할 예정이다.)
- UI 기반의 모니터링 시스템보다 빠르게 확인할 수 있다는 장점이 있다.
_cat/health

- GET /_cat/health?v
- 클러스터의 전반적인 상태를 확인할 수 있다.
확인할 수 있는 값
- epoch: 에포크 시간
- timestamp: 타임스탬프
- cluster: 클러스터의 이름
- status: 클러스터의 상태
- green: 프라이머리 샤드, 레플리카 샤드 모두가 정상적으로 각 노드에 배치되어 동작하고 있는 상태
- yellow: 프라이머리는 정상적으로 동작하지만, 일부 레플리카 샤드가 정상적으로 배치되지 않은 상태, 색인 성능에는 이상이 없지만, 검색 성능에는 영향을 줄 수 있다.
- red: 일부 프라이머리 사드와 레플리카 샤드가 정상적으로 배치되지 않은 상태, 색인 성능과 검색 성능에 영향을 주며, 문서 유실이 생길 수 있습니다.
- node.total: 노드의 개수
- node.data: 데이터 노드 개수
- shards: 클러스터의 샤드
- pri: 프라이머리 샤드 개수
- relo: 재배치가 일어나고 있는 샤드의 수 (데이터 노드를 클러스터에 추가하면, 샤드를 옮기거나 해야하니까)
- init: 지금 만들어지고 있는 샤드의 수
- unassign: 샤드들 중에 아직 노드에 배치되지 않은 샤드 수 → 이게 있어서 클러스터의 상태가 옐로우 였던 것
- p ending_tasks:
- max_task_wait_time:
- active_shards_percent:
_cat/nodes

- _cat/nodes
- 노드들의 전반적인 상태를 확인 할 수 있다.
확인할 수 있는 값
- ip: 노드의 IP
- heap.percent: 힙 메모리 사용량 = jvm의 메모리
- ram.percent: 메모리 사용량 = 노드의 메모리
- cpu: CPU사용량
- load_1m , load_5m , load_15:로드 에버리지
- node.role: 노드의 역할 (마스터노드, 인제스트, 데이터 등등)
- master:마스터 노드인지 , * 표시 = 마스터 노드다
- disk.avail: 디스크 얼마나 남아있는지
언제 사용하면 좋을까?
- 노드들의 디스크 용량 확인
- 노드들이 명확한 역할을 수행하고 있는지 확인
- 어떤 노드가 마스터 노드인지 확인
- 노드들의 메모리 사용량 확인
_cat/indices

- _cat/indices
- 인덱스의 상태를 확인할 수 있다.
확인할 수 있는 값
- health: health에서 조회했던 값
- cat health 에서 봤던 상태 정보를 cat indices 에서도 볼 수 있음 클러스터의 상태 = 인덱스의 상태
- status: open/ close 2개의 값이 있는데, close는 색인이 불가능한 상태를 의미함
- index:인덱스의 이름
- pri: 프라이머리 샤드의 개수
- rep: 레플리카 샤드의 개수
- docs.count: 문서의 수
- store.size: 인덱스의 전체 데이터의 크기(프라이머리 + 레플리카)
- pri.store.size: 프라이머리기준 데이터의 크기
언제 사용하면 좋을까?
- 인덱스들의 프라이머리 샤드 개수와 레플리카 개수 확인
- 이상 상태인 인덱스 확인
_cat/shards
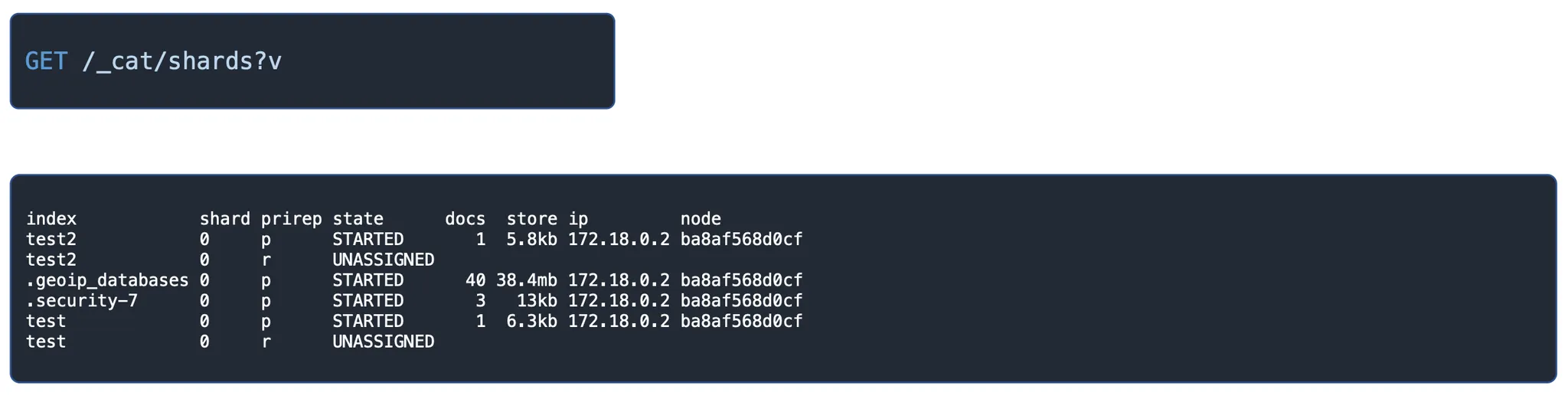
- _cat/shards
- 샤드의 상태 확인할 수 있다.
- 클러스터의 모든 값을 조회할 수 있다.
확인할 수 있는 값
- shard: 몇 번쨰 샤드인지
- prirep: 프라이머리인지 레플리카인지
- state: unassigned / started 등이 있는데, unassigned라면, yellow 상태임
- unassigned.reason: 왜 unassigned라고 뜨는지에 대한 항목
언제 사용하면 좋을까?
- 이상 상태인 샤드들 확인
- 이상 상태의 원인 확인
정리
- cat health 를 통해 상태확인
- 만약 yellow나 red가 나왔다면, cat indices를 이용해 어떤 인덱스가 문제인지 확인
- cat shard 를 이용해 해당 인덱스에서 unassigned인 샤드와 원인에 대해 확인
주요 모니터링 지표 살펴보기
모니터링이란?
- 모니터링
- 이상 징후를 감지하고 필요한 정보를 바탕으로 전파 하는 것
모니터링 시스템 구축
- Elastic Cloud: 엘라스틱 클라우드를 사용하는 경우 → kibana의 stack monitoring
- Self-Hosted ElasticSearch: 직접 엘라스틱서치 클러스터를 구축하는 경우 → kibana의 stack monitoring
- AWS OpenSearch Service: AWS의 오픈 서치 서비스를 이용하는 경우 → AWS Cloud Watch
그 외 : 프로메테우스, 익스포터
모니터링 지표
주요 지표
- 크게 임계치를 걸어서 알람을 받아야 하는 지표
- 문제 원인을 찾아내기 위해 분석용도로 사용하는 지표
종류  주황색: 알림을 받을 지표, 초록색: 원인 분석 지표
주황색: 알림을 받을 지표, 초록색: 원인 분석 지표
알림을 받을 지표
- CPU Usage
- 노드가 지금 CPU를 얼마나 사용하고 있는가
- 노드가 얼마나 많은 요청을 받고 있는가
- 노드가 얼마나 바쁜가
- 임계치: 50% → 계속해서 50% 이상이라면, 노드를 늘리거나 스케일 업하는 처리를 할 수 있음
- 노드가 얼마나 많은 요청을 받고 있는가
- Disk Usage(Disk Free Space)
- 노드의 디스크 사용량
- 노드가 얼마나 많은 문서를 저장하고 있는가
- 임계치 : 70% → 70% 이상이라면, 데이터 노드를 늘려 스프레드 시키거나 더 큰 용량의 디스크로 변경
- 노드가 얼마나 많은 문서를 저장하고 있는가
- Load
- 부하와 관련된 수치
- CPU Usage와 밀접한 관련이 있음
- 노드가 얼마나 많은 CPU와 디스크 연산을 처리하고 있는가
- 노드가 처리하고 있는 프로세스의 수가 얼마인가
- 임계치 : CPU 개수에 따라 상이, CPU 개수 이상으로 설정 = CPU 개수보다 더 많은 프로세스가 계속 실행되고 있기 때문
- CPU Usage와 밀접한 관련이 있음
- JVM Heap
- 노드의 JVM이 얼마나 많은 메모리를 사용하는가
- 관리하지 않으면 OOM(Out Of Memory)가 발생됨
- GC와 관련되어있음
- 임계치 : 85% = GC에 문제가 발생해 올드 영역에 비워지지 않고 있다는 의미
- 관리하지 않으면 OOM(Out Of Memory)가 발생됨
- Threads
- 처리량을 넘어서는 색인/검색 요청이 있는가
- Queue와 Reject: elasticsearch는 노드안에 순간적으로 많은 요청이 들어올때 queue안에 잠시 보관하는 기능이 있음, 이때 이 queueq까지 다 차버리면 더이상 처리할 수 없어 reject 함 → 요청 에러 발생
- 이런 Queue와 Reject에 관련된 지표를 보여줌
- 임계치 : rejected thread가 1 이상 = rejected thread가 존재해서는 안됨
- Queue와 Reject: elasticsearch는 노드안에 순간적으로 많은 요청이 들어올때 queue안에 잠시 보관하는 기능이 있음, 이때 이 queueq까지 다 차버리면 더이상 처리할 수 없어 reject 함 → 요청 에러 발생
원인 분석 지표
- memory Usage
- 노드에 설치되어 있는 물리적 메모리의 사용량
- JVM Heap과는 다름
- 힙 메모리 때문에 발생하는 이슈를 해결할 수 있을지 없을지 판단하는 중요한 지표
- JVM Heap과는 다름
- DIsk I/O
- 노드에서 발생하는 디스크 연산의 지연 시간
- 디스크에 저장하기 위해서 얼마나 많은 작업을 해야하는가
- 해결 방법: 디스크 자체를 좋은 디스크로 변경하거나, 불필요한 입출력 연산인지 등을 확인함
- 디스크에 저장하기 위해서 얼마나 많은 작업을 해야하는가
- GC Rate
- 노드에서 발생하는 GC의 발생 주기
- 성능에 문제가 있을 때, 확인해 볼 만한 지표
- GC Duration
- 노드에서 발생하는 GC의 소요 시간
- Latency
- 노드에서 색인 및 검색에 소요되는 시간
- Rate
- 노드에서 색인 및 검색 요청이 인입되는 양
This post is licensed under CC BY 4.0 by the author.