ElasticSearch Essential - 02 살펴보기
클러스터, 노드, 인덱스, 샤드, 매핑에 대한 이해
Elasticsearch 소개
Elasticsearch
- Elasticsearch
- elasticsearch는 루씬(Lucene) 이라는 라이브러리를 이용해 만들어진 거대 애플리케이션이다.
- JSON 기반의 문서를 저장하고, 검색할 수 있으며 분석 작업도 가능하다.
- 루씬(Lucene)
- 자바 기반의 오픈소스 라이브러리로, 강력한 텍스트 검색 엔진 라이브러리이다.
- 문서를 색인하고 검색하는 기능을 제공한다.
- 데이터베이스가 아닌, 검색 기능을 위한 라이브러리이다.
- elasticsearch, Solr 같은 검색 엔진의 핵심 기술이다.
Elasticsearch 특징
- 준실시간 검색 시스템
- 실시간이라고 생각될 만큼 색인된 데이터가 빠르게 검색된다.
- elasticsearch 내에 문서가 색인되면, 색인 결과가 메모리에 올라가서 검색을 할 수 있게 된다.
refresh-interval이라는 설정값을 통해 얼마나 빨리 검색될 수 있도록 할 것인지를 설정할 수 있다. - elasticsearch 내에 문서가 색인되면, 색인 결과가 메모리에 올라가서 검색을 할 수 있게 된다.
- 고가용성을 위한 클러스터 구성
- 한 대 이상의 노드로 클러스터를 구성하여 높은 수준의 안정성을 달성하고, 부하 분산이 가능하다.
- 클러스터 내부의 노드가 여러개면, 트래픽을 그만큼 나눠서 처리할 수 있기 때문에 부하 분산이 가능하다. 또한, 노드 여러 개면, 하나의 노드가 죽어도 나머지 노드들이 처리할 수 있어 안정성이 높아진다.
- 동적 스키마 생성
- 입력될 데이터들에 대해 미리 스키마를 정의하지 않아도 동적으로 스키마 생성이 가능하다.
- REST API를 제공
- REST API 기반의 인터페이스를 제공해 비교적 사용을 위한 진입 장벽이 낮다.
클러스터와 노드 이해하기
노드(Node)의 종류
버전이 올라감에 따라 아래 종류 외에도 더 있고, 노드마다 역할이 늘어나기 때문에 공통적인 부분만 작성
- 마스터 노드
- 클러스터 상태 관리 및 메타데이터 관리한다.
- 마스터 후보 노드
- 마스터 노드에 문제가 생겼을 때 바로 마스터 노드가 될 수 있는 후보 노드이다.
- 마스터 노드와 마스터 후보 노드의 관계
- 마스터 노드
- 현재 클러스터 내에서 마스터 노드의 역할을 하고 있는 노드로, 클러스터 내에 1개만 존재한다.
- 마스터 후보 노드
- 마스터 노드에 문제가 생겨 죽으면, 마스터 후보 노드들 중에서 새로운 마스터를 뽑아낸다.
설정 중에 노드의 역할을 설정하는 내용이 있는데, 이 설정은 실제 마스터 노드를 지정하는 값이 아닌 마스터 역할을 할 수 있는 노드를 지정하는 설정이다. 실제 마스터 노드는 이렇게 설정된 노드들 중 하나가 된다.
- 데이터 노드
- 문서 색인 및 검색 요청 처리한다.
- 코디네이팅 노드
- 검색 요청 처리한다.
- 인제스트 노드
- 색인되는 문서의 데이터 전처리한다.
인제스트 노드의 데이터 전처리란? 어떤 문서가 elasticsearch에 들어와서 저장이 되기 전에 문서를 수정한다는 의미
클러스터(Cluster)
- 클러스터
- 컴퓨터 클러스터는 여러 대의 컴퓨터들이 연결되어 하나의 시스템처럼 동작하는 컴퓨터들의 집합을 의미한다.
- Elasticsearch 클러스터
- 여러 대의 노드들이 각자의 역할을 바탕으로 연결되어 하나의 시스템처럼 동작하도록 되어있다.
- 클러스터 성능이 부족하면 노드를 늘려서 대응할 수 있지만, 노드를 늘린다고 모두 성능이 좋아지진 않는다.
- 어떤 노드에 어떤 요청을 해도 동일한 응답을 해준다.
- 클러스터 성능이 부족하면 노드를 늘려서 대응할 수 있지만, 노드를 늘린다고 모두 성능이 좋아지진 않는다.
클러스터의 특징: 어떤 노드에게 어떤 요청을 해도 동일한 응답을 준다.
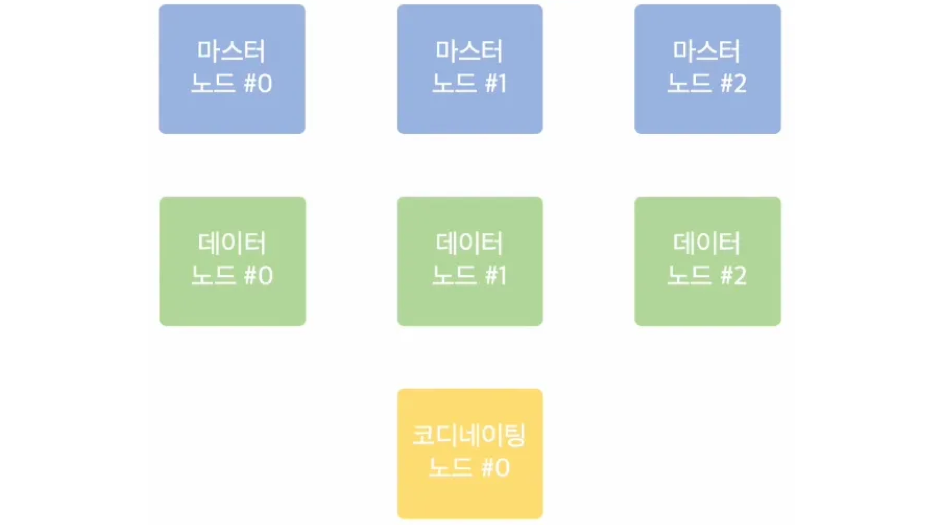 7개의 노드가 하나의 클러스터를 이루고 있는 상황을 가정, 검색 요청에 대해 처리해야하는 상황
7개의 노드가 하나의 클러스터를 이루고 있는 상황을 가정, 검색 요청에 대해 처리해야하는 상황
client의 요청이 마스터 노드가 아닌, 실제 데이터를 가지고 있는 데이터 노드로에게 가야할 것 같지만 elasticsearch는 클러스터이기 때문에 누구에게 요청을 해도 상관없다. 이 내용을 마스터 노드가 검색 요청을 받은 상황과 데이터 노드가 검색 요청을 받을 상황을 비교해 살펴보자.
상황 1. 마스터 노드에게 데이터 검색 요청한 상황 마스터 노드 #0가 마스터 노드, 마스터 노드 #1, 마스터 노드 #2가 마스터 후보 노드인 상황이다.
마스터 노드 #0가 요청을 받는다.- 마스터 노드는 검색 요청 처리를 안할 것이라고 오해할 수 있지만, 마스터 노드도 처리한다.
데이터 노드 #0에게 데이터 요청한다.- 마스터 노드는 실제 데이터를 가지고 있지 않기 때문에 실제 데이터를 가지고 있는 데이터 노드에게 데이터를 받아서 해당 값을 보냄
데이터 노드 #0은마스터 노드 #0에게 데이터를 준다.마스터 노드 #0은 응답한다.
상황 2. 데이터 노드에게 데이터 검색 요청한 상황
데이터 노드 #0가 데이터 검색을 요청을 받는다.데이터 노드 #0은 데이터를 검색한다.데이터 노드 #0은 응답한다.
결과: 마스터 노드에게 요청해도 데이터 노드와 똑같은 결과를 받을 수 있음 ⇒ 클러스터이기 때문에
이와 같은 원리로, 원래 코디네이팅 노드는 검색을 담당하는 노드지만 코디네이팅 노드에게 색인 요청을 해도 잘 동작한다.
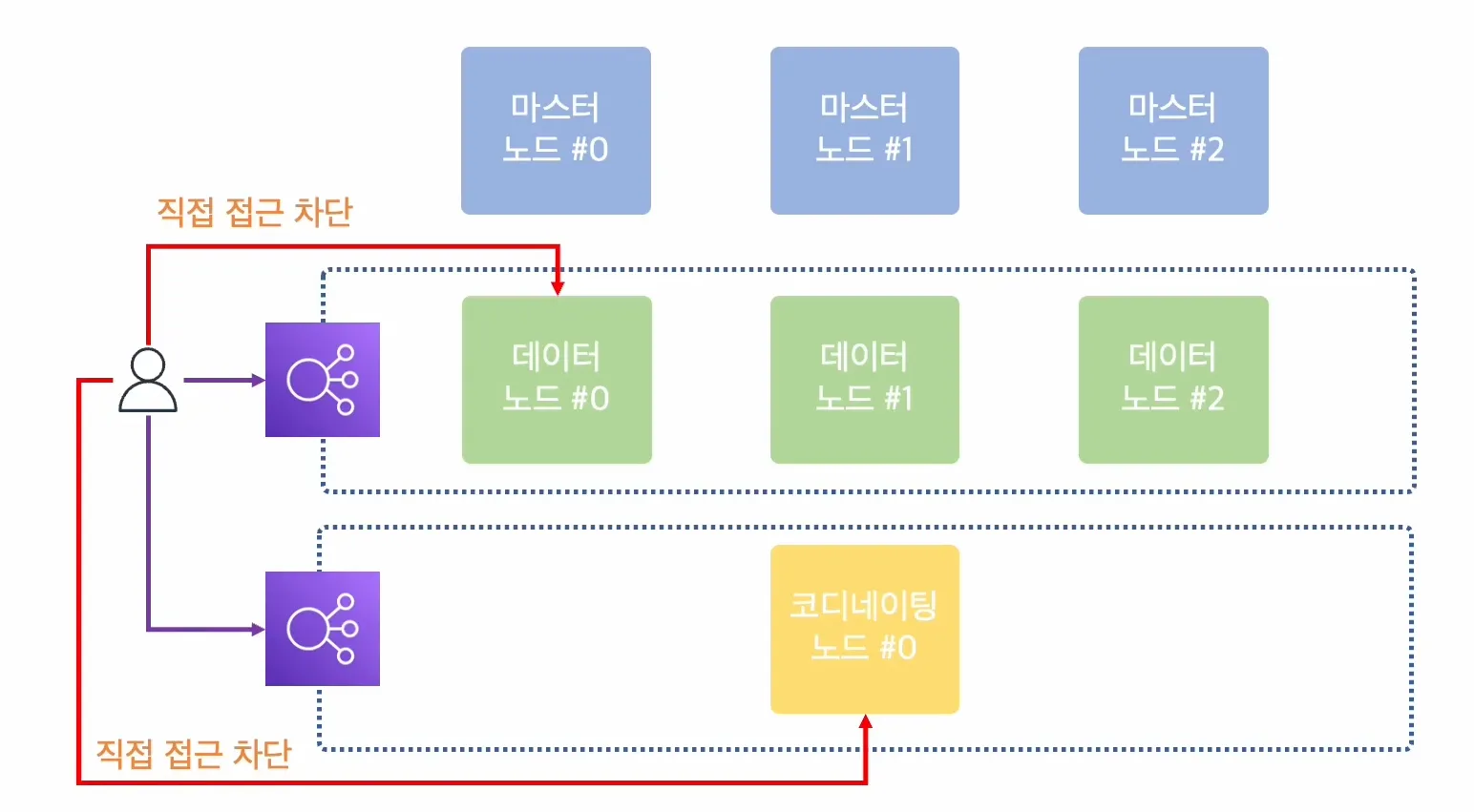
이상적인 클러스터 구성 모든 노드가 어떤 요청을 받아도 잘 처리하지만 효율적으로 동작하려면, 각자 역할에 맞는 요청을 하는 것도 중요하다.
각 노드에 직접 접근을 막고, 로드 밸런서를 추가한뒤 각 로드밸런서에 end-point를 생성해 로드 밸런서를 통해 접근할 수 있도록한다. 노드의 수가 변화하는 상황에서도 유연하게 대응이 가능하고, 각자 역할에 맞는 end-point를 호출함으로써 효율적으로 동작할 수 있다.
인덱스와 샤드 이해하기
인덱스(Index)
- 인덱스
- 문서가 저장 되는 논리적인 공간이다.
- 문서를 저장하기 위해서는 반드시 인덱스가 존재해야한다.
- RDBMS에서 database와 비슷한 개념으로 생각할 수 있다.
- Elasticsearch 인덱스를 설계하는 것이 Elasticsearch를 사용하기 위해 고려해야하는 첫번째 단계이다.
- 문서를 저장하기 위해서는 반드시 인덱스가 존재해야한다.
인덱스의 설계
인덱스 설계에 따라 문서의 구조와 쿼리 방식이 달라지기 때문에, 사용 패턴과 문서의 특성에 따라 설계해야한다.
설계 방식에 따른 장단점
- 하나의 인덱스만 사용시
- 장점: 관리할 인덱스 수가 1개라 관리 리소스가 적게 발생한다.
- 단점: 쿼리와 문서의 구조가 복잡해질 수 있다.
- 여러개의 인덱스만 사용시
- 장점: 각각의 경우에 최적화된 쿼리와 문서 구조를 사용할 수 있다.
- 단점: 관리할 인덱스 수가 많아 관리 리소스가 발생할 수 있다.
시스템이 얼마나 커질지 등이 예측이 어렵다면, 초반에는 하나의 인덱스로 단순하게 시작한뒤 이후에 나타나는 사용 패턴에 따라 인덱스를 별도로 운영하는 방식을 권장한다.
샤드(Shard)
- 샤드
- 인덱스에 색인되는 문서가 저장되는 공간이다
- 하나의 인덱스는 반드시 하나 이상의 샤드를 가진다.
샤드의 종류
- 프라이머리 샤드
- 문서가 저장되는 원본 샤드이다.
- 색인과 검색 성능에 모두 영향을 준다.
- 레플리카 샤드
- 프라이머리 사드의 복제 샤드이다.
- 검색 성능에 영향을 준다.
- 프라이머리 샤드에 문제가 생기면 레플리카 샤드가 프라이머리 샤드로 승격된다.
- 검색 성능에 영향을 준다.
색인 과정
- 프라이머리 샤드에서 문서를 분석한다.
많은 리소스를 사용하는 과정으로, 프라이머리 샤드가 색인 성능에 영향을 주는 이유이다.- 토커나이징을 한 뒤 프라이머리 샤드에 저장한다.
- 저장이 완료되면, 저장한 내용을 레플리카 샤드로 복제한다.
마지막에 레플리카 샤드로 내용을 복제하는 과정도 있어, 레플리카 샤드가 색인 성능과 관계가 없다고 할 수는 없다.
샤드 설정
number_of_shards- 프라이머리 샤드의 수를 의미한다.
- 기본 값은 1로 되어있다.
number_of_replicas- 1개의 프라이머리 샤드당 복제되는 레플리카 샤드를 의미한다.
- 샤드 라우팅
- 문서가 샤드에 저장되는 순서, 저장되는 방법을 의미한다.
- 라우팅 룰 계산식(
Routing Rule = (문서의 ID) % (샤드의 개수))으로 이용해 여러개의 샤드에 문서가 고르게 저장된다.- 그러나 중간에 샤드의 개수가 바뀐다면, 문서가 저장되는 규칙이 완전히 바뀌게된다. = 인덱스 생성 이후 샤드의 개수를 바꿀 수 없는 이유
- 라우팅 룰 계산식(
인덱스 생성 이후 샤드의 개수를 바꿀 수 없다 프라이머리 샤드는 인덱스 생성 후 변경할 수 없지만, 레플리카 샤드는 변경할 수 있다. 위 설명에서 말한 샤드는 모두 프라이머리 샤드를 기준으로 생각하면 된다.
- 인덱스 템플릿
- 샤드의 설정은 중요한데, 인덱스 생성시 매번 설정하는 것은 누락되기 쉽고 번거로워 이것에 대한 설정 값을 저장해놓고 인덱스 생성시마다 해당 설정값으로 인덱스가 생성되도록 하는 기능이다.
- 인덱스의 이름을 기준으로 패턴을 지정하면, 해당 패턴에 맞는 인덱스 생성시 자동으로 적용된다.
매핑 이해하기
매핑
- 매핑
- 문서의 구조를 나타내는 정보
- Elasticsearch는 완전히 스키마리스(Schema-less)는 아니지만, 동적 매핑을 지원한다.
매핑의 종류
- 동적 매핑(Dynamic Mapping)
- 처음 색인되는 문서를 바탕으로 매핑 정보를 Elasticsearch가 동적으로 생성한다.
- 어떤 문서가 색인될지 스키마를 미리 정의하지 않아도 된다.
- 정적 매핑(Static Mapping)
- 문서의 매핑 정보를 미리 정의한다.
- 어떤 문서가 색인될지 스키마를 미리 정의한다.
- 문서의 필드들이 가지는 값에 따라 타입을 지정해 줄 필요가 있을 때 사용된다. ex) 실수 타입의 기본형이
float이지만,double로 지정해야 할때- 불필요한 색인이 발생하지 않게 제한하고 싶을 때 사용된다. ex)
text필드는 자동으로keyword타입이 생성되는데keyword가 사용되지 않아 막고싶을때 - 어떤 문서가 색인될지 스키마를 미리 정의한다.
일부 필드만 정적 매핑으로 지정한다면, 나머지 필드들은 동적매핑으로 진행된다.