Springboot Jpa - JPA 소개
jdbc를 이용해 DB에 접근하던 방식에서, 마지 JAVA의 Collection을 접근하는 방식과 유사하게 DB에 접근할 수 있게 해주는 JPA에 대해 알아보자. JPA가 주는 편리함과 설명을 찾아보자.
Springboot Jpa - JPA 소개
강의 목표
- 객체와 테이블 설계 매핑
- 객체와 테이블을 제대로 설계하고 매핑하는 방법
- 키본 키와 외래 키 매핑
- 1:N, N:1, 1:1, N:M 매핑
- 실무 노하우 + 성능까지 고려
- 어떠한 복잡한 시스템도 JPA로 설계 가능
- JPA 내부 동작 방식 이해
- JPA의 내부 동작 방식을 이해하지 못하고 사용
- JPA 내부 동작 방식을 그림과 코드로 자세히 설명
- JPA가 어떤 SQL을 만들어 내는지 이해
- JPA가 언제 SQL을 실행하는지 이해
SQL 중심적인 개발의 문제점
SQL 중심적인 개발의 문제점은 무엇인가?
SQL에 의존적인 개발
단순 반복의 CRUD 작업
패러다임의 불일치
객체 지향의 객체와 관계형 데이터베이스의 테이블이 비슷하지만 다른점이 존재한다.
상속
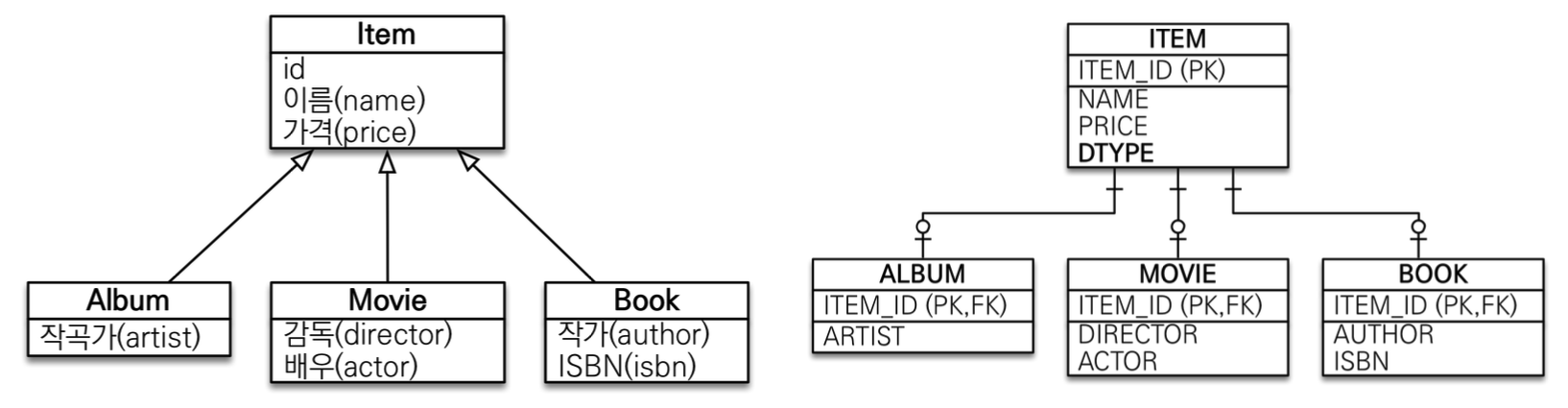 객체의 상속 관계, RDB의 슈퍼타입 서브타입 관계
객체의 상속 관계, RDB의 슈퍼타입 서브타입 관계
문제점
- RBD에서 작업시 단순 query보다 복잡한 쿼리를 작성해야한다.
- 데이터 추가시, 1개의 객체 데이터를 추가할 때 마다, 2개의 테이블(item, album등)에 데이터를 추가해야한다.
- 데이터 조회시, album, book, movie 조회시 join query를 작성해야한다.
연관관계
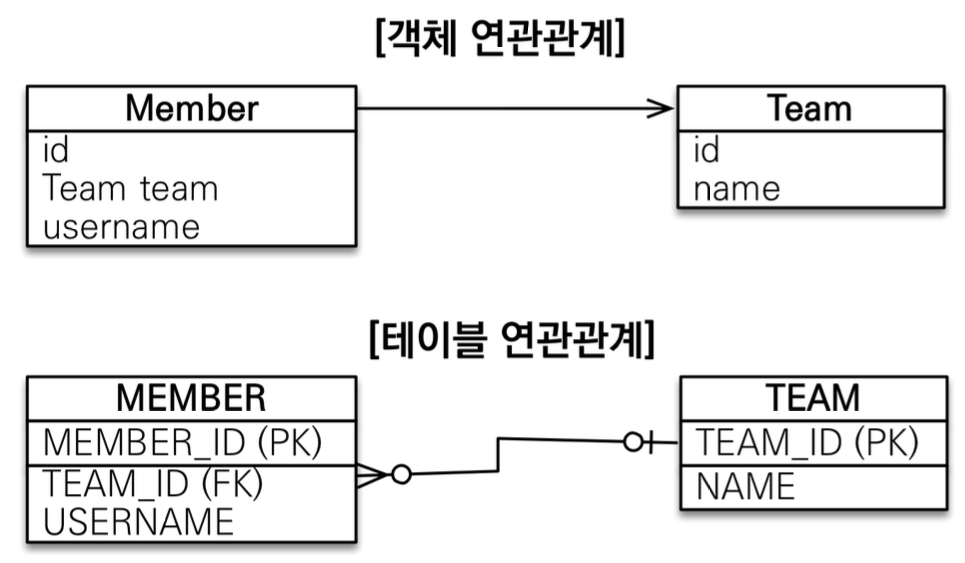 객체의 참조, RDB의 외래키 사용
객체의 참조, RDB의 외래키 사용
문제점
- 객체에 맞춰 테이블을 맞추어 모델링하게 된다.
- RDB에서 작업(=CRUD) 할 때 편리하기 위해서 테이블의 모델링 방식을 객체에 맞추게 된다.
- 객체는 참조를 사용할 때, join query를 작성해야한다.
데이터 타입
문제점
- 객체내에 참조가 여러번 있는 경우에 DB에서 조회한 객체에서 안쪽에 있는 참조들까지 데이터가 있는지 확신하기 어렵다.
- 그렇다고 매번 모든 데이터를 조회하도록 query를 작성하기엔 너무 비효율 적이다.
- 보통은 이를 해결하기 위해 조회되는 범위를 DAO의 이름에 넣게 되는데, 각 케이스마다 작성해야해서 굉장히 비효율적이다.
- 계층형 아키텍처에서 진정한 의미의 계층 분할이 어렵다.
- 물리적으로는 분리되어있지만, 논리적으로는 엮여있다.
데이터 식별 방법
1
2
3
4
5
int id = 1;
User user1 = userDAO.getUser(id);
User user2 = userDAO.getUser(id);
user1 != user2; // 다르다.
1
2
3
4
5
int id = 1;
User user1 = list.get(id);
User user2 = list.get(id);
user1 == user2; // 같다.
문제점
- DB에서 조회한 내용으로 인스턴스를 새로 생성하기 때문에, 같은 id로 조회한
User라도==이 아닌 다른 연산을 통해 같은 객체인지 확인해야한다.
JPA 소개
그 대안으로 나온 JPA는 어떤 역할을 하는가?
JPA란?
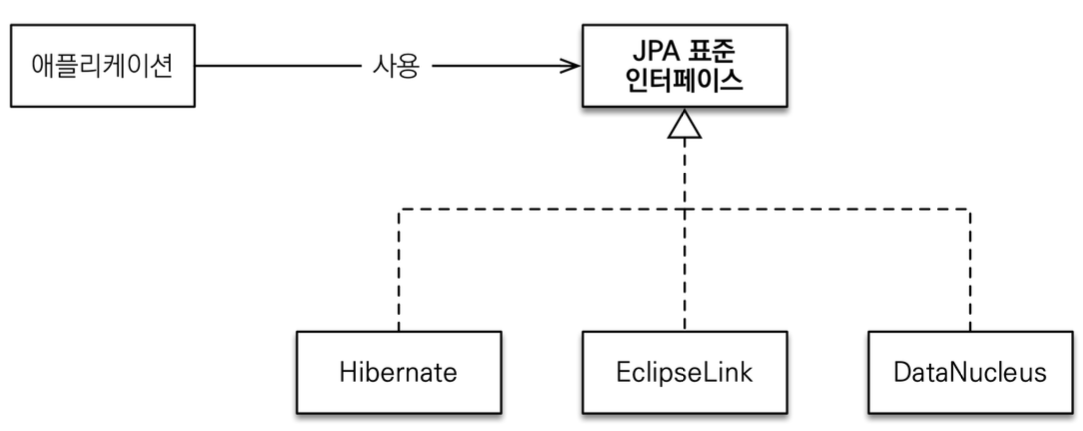
- JPA(Java Persistence API)란?
- 자바 진영의 ORM 기술 표준으로, 인터페이스의 모음이다.
- JPA 2.1 표준 명세를 구현한 Hibernate, EclipseLink, DataNucleus 라는 3가지 구현체가 있는데, 주로 Hibernate를 사용한다.
- ORM(Object-relacation Mapping)이란?
- 객체는 객체대로 설계 하고, 관계형 데이터베이스는 관계형데이터베이스대로 설계하여 ORM 프레임워크가 중간에서 매핑해주는 역할을 한다.
- 대중적인 언어에는 ORM이 존재한다.
JPA의 동작
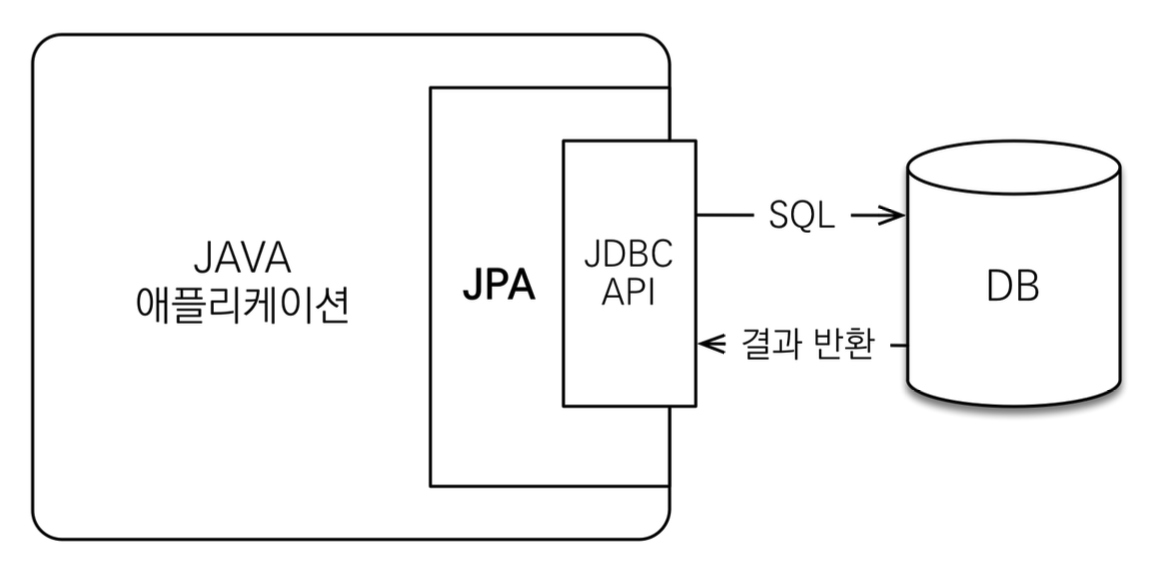 JPA가 동작하는 위치
JPA가 동작하는 위치
- 저장
- java->JPA: entity를 보내며, 저장하라고한다.
- JPA: entity를 분석 -> insert query 생성 -> jdbc api를 이용해 DB에 접근 + 패러다임 불일치 해결
- 조회
- java->JPA: 조회할 id를 주며, 조회해달라고한다.
- JPA: select query 생성 -> jdbc api를 이용해 DB에 접근 -> result set 매핑 + 패러다임 불일치 해결
- JPA -> java: entity 리턴
왜 JPA를 사용해야 하는가?
- SQL 중심적인 개발에서 객체 중심으로의 개발
- 마치 java의 컬렉션에 저장하듯, DB를 다룰 수 있게 된다.
- 이로 인해 생산성이 크게 증가한다.
- 유지보수
- 필드 변경시, 모든 query를 수정하지 않아도 된다.
- 패러다임 불일치 해결
- 상속, 연관관계, 객체 그래프 탐색, 비교에 대해, JPA가 분석하고 적절하게 처리를 함으로써 관련된 문제를 해결해준다.
- 그로 인해 신뢰할 수 있는 엔티티를 신뢰할 수 있게된다.
- 성능
- 1차 캐시와 동일성 보장 - 같은 트랜잭션 안에서는 같은 엔티티를 반환해 동일성 보장하고, 약간의 조회 성능도 향상된다.
- 트랜잭션을 지원하는 쓰기 지연 - 트랜잭션을 커밋할 때까지 insert query를 모아 한번에 전송한다.
- 지연 로딩과 즉시 로딩 - 객체가 실제 사용될 때 로딩하는 지연로딩과 join query로 한번에 연관된 객체까지 미리 조회하는 즉시로딩을 지원하고, 설정을 통해 변경이 가능하다.
- 트랜잭션을 지원하는 쓰기 지연 - 트랜잭션을 커밋할 때까지 insert query를 모아 한번에 전송한다.
This post is licensed under CC BY 4.0 by the author.