Nosql?LSM tree?
LSM tree는 무엇이고, B+tree와는 어떻게 다를까
LSM Tree란?
- LSM Tree(로그 구조 병합 트리, LSMT)
- Log Structured Storage Engine 중 하나 입니다.
- key-value 형식으로 데이터가 저장됩니다.
- Nosql DB 중 일부(RocksDB, Cassandra, HBase 등)가 LSM Tree를 기반으로 합니다.
- key-value 형식으로 데이터가 저장됩니다.
Nosql DB로 유명한 mongoDB는 LSM tree 기반이 아닙니다.
- Log Structured Storage Engine
- LogFile을 기반으로 작동하는 방식
- LogFile
- Append-only 파일
- 한번 쓰여진 정보는 바뀌지 않고, 새로운 내용은 항상 파일의 끝에 추가되는 파일
LSM Tree 구조
LSM tree는 데이터를 데이터를 하나로 저장하지 않고, 2개의 트리(MemTable, SSTable)에 나눠서 저장합니다.
MemTable- LSM Tree에서 메모리에서 데이터를 관리하는 곳 입니다.
MemTable에는 데이터가 트리의 구조로 정렬되어 있습니다.MemTable에서 관리하는 데이터의 양이 임계치를 넘어가게되면,SSTable로 데이터를 옮깁니다.SSTable에 저장되기 전까지는 Log File을 Disk에 작성해 서버 장애 발생시에도 데이터가 누락되지 않도록 관리됩니다.LSM tree에서 LogFile
MemTable에서SSTable로 데이터가 옮겨질때, LogFile의 모든 내용도 삭제합니다. Append Only로 동작하기 때문에, 데이터가 한번 입력된 이후 데이터를 수정하더라도 내용이 수정되지 않고, 파일 끝에 추가됩니다. SSTable(Sorted String Table)- LSM Tree에서 데이터를 디스크에 관리하는 곳 입니다.
- 이후에 설명 하겠지만,
SSTable은 디스크 내에 여러개로 존재합니다.- 여러개의
SSTable이 병합 됩니다.SSTable의 데이터는 변하지 않는 데이터(immutable)로, 수정되지 않습니다. - 이후에 설명 하겠지만,
LSM tree의 동작 과정
LSM Tree의 데이터 쓰기
LSM tree에서 데이터를 쓴다고 하면, 데이터는 어떻게 저장될까요?
이미지가 잘 안보이는데, 클릭하면 확대가 가능합니다.
데이터의 MemTable의 임계치를 4라고 가정한 상태에서 데이터 입력 과정을 작성했습니다.
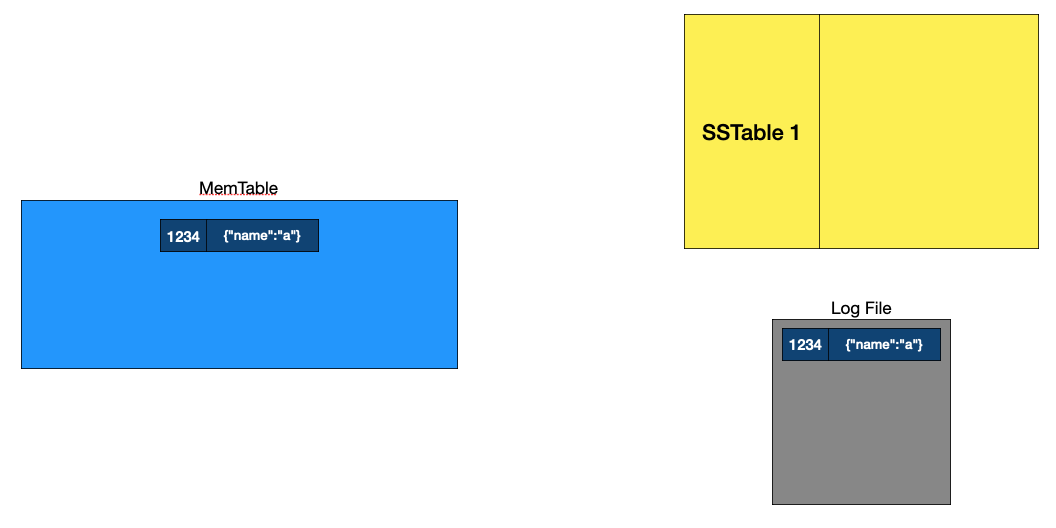
첫번째 데이터 삽입
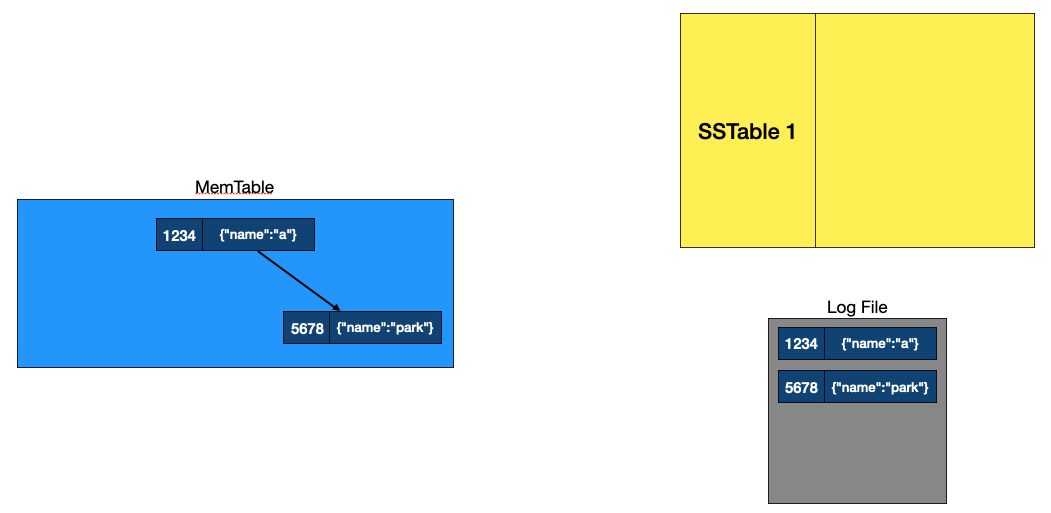
두번째 데이터 삽입
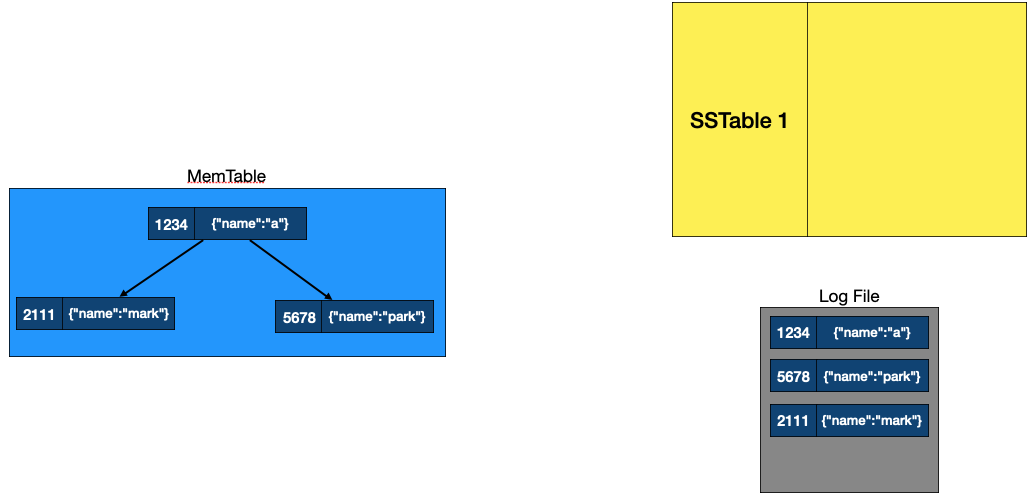
세번째 데이터 삽입
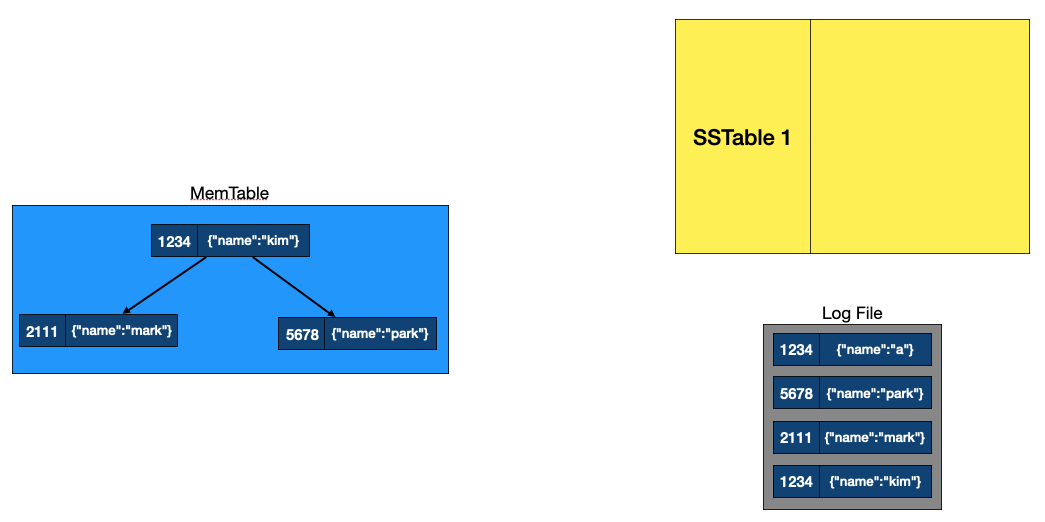
첫번째 데이터 수정
저장
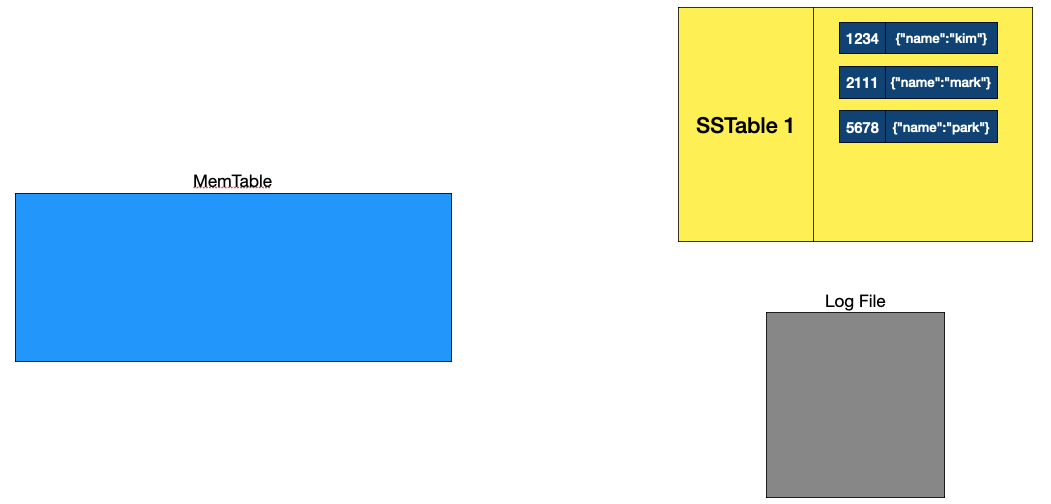
데이터 쓰기 과정, 출처: NoSQL 데이터베이스가 빠른 이유, LSM Tree 완전정복, DB 의 데이터 저장 방법
- 1~4번의 과정까지는 데이터가 들어오는대로
MemTable과 LogFile에 저장합니다.- 1번째로 들어온 데이터가 이후 4번의 과정에서 수정되는데, LogFile에는 데이터가 추가된 것처럼 동작하고,
MemTable에서는 데이터가 수정되는 것을 볼 수 있습니다.
- 1번째로 들어온 데이터가 이후 4번의 과정에서 수정되는데, LogFile에는 데이터가 추가된 것처럼 동작하고,
- 5번 과정처럼 일정 단위가 되서
SSTable로 데이터를 옮기면MemTable과 LogFile의 내용은 지웁니다.
LSM Tree의 데이터 읽기
단일 데이터 읽기
이렇게 데이터가 저장되면, 어떻게 데이터를 읽어올까?
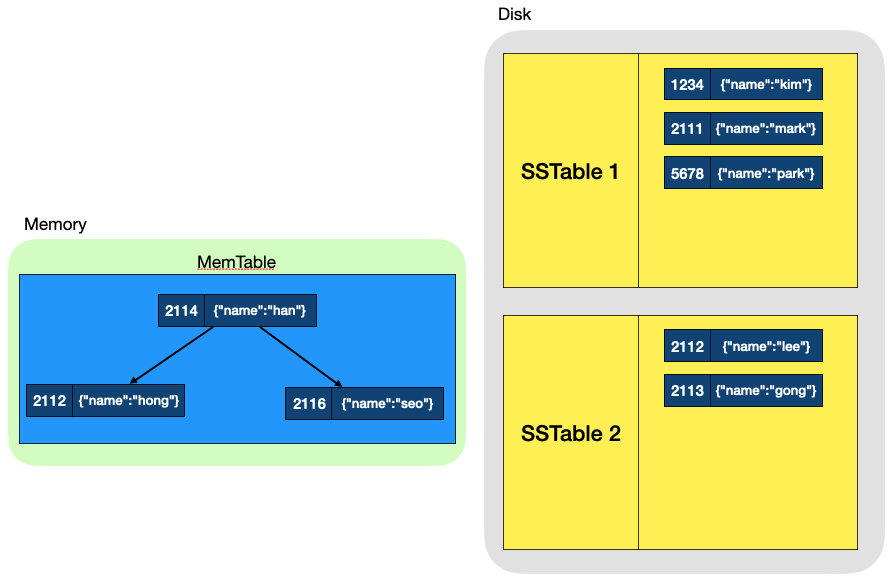
SSTable은 데이터가 계속 저장됨에 따라 계속 늘어나지만 일단 2개가 있다고 가정해 봅시다.
이 상태에서 key값이 2113인 데이터를 찾는 과정은 아래와 같습니다.
MemTable에서 조회- 없으면
SSTable-1에서 조회 - 없으면
SSTable-2에서 조회
이렇게 된다면, 데이터가 MemTable에 있었다면 빠를 것이고, SSTable-2와같이 Disk에 있는 데이터 중 마지막 데이터라면 매우 느립니다. 최악의 경우에는 모든 데이터를 다 확인해야한다는 단점이 있죠. 물론, 각 SSTable 안에는 데이터가 정렬되어있어 빠르게 검색할 수 있지만, SSTable은 disk에 있어 Memory보다는 느립니다.
그러면 메모리에 인덱스가 있으면 좋지 않을까요? 그래서 인덱스가 상황을 가정해보겠습니다.
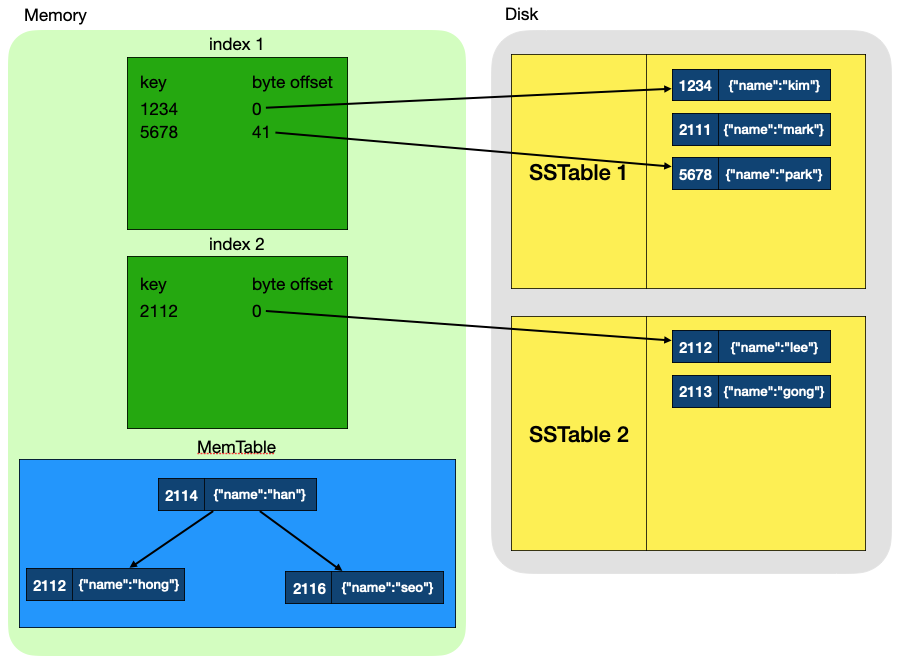 출처: NoSQL 데이터베이스가 빠른 이유 | LSM Tree 완전정복 | DB 의 데이터 저장 방법
출처: NoSQL 데이터베이스가 빠른 이유 | LSM Tree 완전정복 | DB 의 데이터 저장 방법
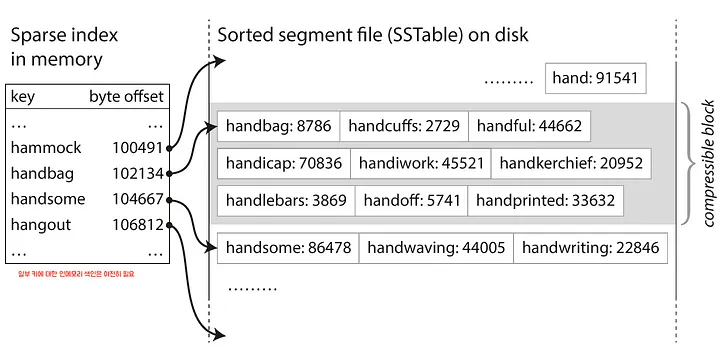
이때의 인덱스는 Hash index로, 각 SSTable의 정보를 key와 byte offset을 가지고 있으며, SSTable의 데이터 시작과 끝의 값만 가지고 있습니다.
그럼 이때 key값이 2113인 데이터 조회 과정은 아래와 같습니다.
MemTable에서 조회- 없으면
index1에서 조회하려는 데이터의 key가 포함되는지 확인 = 조회하려는 데이터의 key가 index의 key 범위에 포함되는지 확인 - 없으면
index2에서 조회하려는 데이터의 key가 포함되는지 확인 = 조회하려는 데이터의 key가 index의 key 범위에 포함되는지 확인 index2에 포함되니까 byte offset을 통해 바로 disk에 있는SSTable-2에 접근SSTable-2내에서 조회
인덱스의 값은 SSTable의 모든 값이 아닌 각 SSTable의 시작값과 마지막 값만 가지고 있는데, SSTable 내의 값은 이미 정렬되어있기 때문입니다.
 인덱스, 출처: 색인(index)의 두 가지 형태 : LSM 트리 & B 트리
인덱스, 출처: 색인(index)의 두 가지 형태 : LSM 트리 & B 트리
범위 데이터 읽기
이렇게하면 특정 데이터를 조회할 때 빠르게 조회할 수 있습니다. 그러면 하나의 데이터가 아니라 여러개의 데이터인데, 범위로 지정해서 조회한다면 어떻게 동작할까요?
범위 쿼리를 한다면, 범위 데이터의 시작점과 끝 점을 찾아 각 데이터에 대해 단일 데이터 조회와 같은 방식으로 동작합니다.
비효율적이지만, Hash기반의 index이기 때문에 나오는 단점입니다.
compaction
SSTable의 데이터는 불변데이터라서, 데이터가 이후에 수정되었을 때 실제 데이터에 접근하여 수정하지 않습니다.
만약 굉장히 예전에 데이터를 작성해 데이터가 추가되어
SSTable-1로 저장되어있는 상태에서, 해당 데이터를 수정한다고 하면, 새로 데이터가 저장되는 것처럼 작성됩니다. 그러면 같은 key를 가진 데이터가SSTable-1와SSTable-N에 중복으로 저장됩니다.
그러면 전체 데이터를 기준으로 했을 때는 중복데이터가 많게 되는데, 결국 디스크 공간 낭비로 이어지게 됩니다. 어떻게 하면 이것을 해결할 수 있을까?
LSM tree는 compaction이라는 과정을 통해 이를 해결합니다.
 compaction 대상을 표시, 출처: 색인(index)의 두 가지 형태 : LSM 트리 & B 트리
compaction 대상을 표시, 출처: 색인(index)의 두 가지 형태 : LSM 트리 & B 트리
- Compaction
- 2개의
SStable을 1개의SSTable로 합치는 과정에서, 중복된 키 값이 있다면 최신 값만 유지하고 나머지 데이터는 버린다.- 각
SSTable은 정렬되어 있는 상태기 때문에 병합 정렬을 사용해 합쳐진다.(merge)- 합쳐진
SSTable에 대해서는 인덱스가 필요 없기 때문에 index의 데이터도 줄인다. - 각
LSM tree의 성능 향상
블룸 필터
- 블룸 필터(Bloom Filter)
- LSM tree에서 검색을 빠르게 하기 위한 방법입니다.
데이터가 존재할 수도 있음이나데이터가 확실히 없음을 알려줍니다. 오탐(false positive)은 가능하지만, 오검(false negative)은 없다. = 데이터가 없는 것은 확실하지만, 데이터가 있는것은 불확실합니다.- Memory에 위치합니다.
- 비트맵을 이용해 구현되어 있습니다.
블룸 필터를 이용해서 검색 속도를 높히는 방법
MemTable에서 조회- 블룸 필터에서 데이터가 있는지 확인한다. 없으면, 여기서 없다고 하기 때문에 없는 데이터에 대해서는 빠르게 알 수 있다.
- 있을 수도 있다고 하면, 인덱스에서 해당 데이터의 내용이 있는지 확인합니다.
- 인덱스를 통해, 디스크 내의 위치값을 빠르게 접근한다.
왜 블룸 필터는 데이터의 존재유무를 확실하게 알려주지 않을까? 블룸 필터의 동작원리에 대해 알아야합니다.
블룸 필터
- 모든 비트가 0으로 초기화된 고정된 길이(m)의 비트 배열을 사용합니다.
- 여러 개(k)의 해시 함수를 사용합니다.
동작 순서
- 삽입한 데이터를 k개의 해시함수를 이용해, k개의 해시값을 얻습니다.
- 각 해시 값을 인덱스로 해서 비트배열의 값을 1로 변경합니다.
- e.g. 결과값이 5, 17, 30이라면 비트 배열의 5, 17, 30번째 값을 1로 변경
- 이 후 데이터를 조회할 때, 조회할 데이터도 k개의 해시함수를 이용해 k개의 해시값을 얻습니다.
- 각 해시 값을 인덱스로 해서 비트배열의 값이 모두 1인지 확인합니다.
- 이 때, 조회할 값과 이전 값 중 하나가 해시 충돌로 인해 같은 값이 나올 수 있습니다.
- 모두 1이라면 있는 것으로 판별하지만, 하나라도 0이라면 없다고 판별합니다.
이렇게 해시 값을 이용할 때
해시 충돌이 발생이나, 해시 값이 겹쳐서 이미 1로 설정된 위치를 다시 사용하는 상황 등의 이유로 오탐은 있을수 있지만,
- 해시 충돌: 서로 다른 데이터가 같은 해시 값을 가질 수 있다.
- 해시 값이 겹쳐서 이미 1로 설정된 위치를 다시 사용하는 상황
- 비트 배열이 1, 2, 3, 4, 5 인상황: A 데이터의 해시 값이 1, 3, 4, B 데이터의 해시 값이 2, 3, 5
- 검색하는 값의 해시 값은 1, 2, 5인 경우
이 때, 비트맵은 1에서 0으로는 값을 바꾸지 않기 때문에 오검은 없게 됩니다.
Level Compaction
- Level Compaction
- 디스크 공간을 최적화하고 조회 성능을 높이기 위한 전략입니다.
Level 0부터 시작해서Level N까지 계층적으로 관리되며, 각 레벨의SSTable의 수가 임계치를 초과하면 Compaction을 수행합니다.Level 0의SSTable은 각 내용은 정렬되어 있지만,Level 0인SSTable을 전체를 봤을 때에는 정렬되어 있지 않습니다.
Level Compaction의 동작 방식
Level 0->Level 1:Level 0의SSTable여러 개를 한번에 compactionLevel 0을 전체를 봤을 때에는 정렬되어 있지 않고, 서로 겹칠 수 있기 때문에 여러개를 한번에 compactionLevel 1부터는 서로가 겹치는 일을 막기 위해Level 0뿐만 아니라Level 1의 모든SSTable을 한번에 Compaction한 뒤 적절한 크기로 나눈다.
Level 1이상:Level n의SSTable을 하나 선택하고,Level n+1에서는 선택된SSTable과 키가 겹치는 범위를 찾아 Compaction을 한뒤 적절한 크기로 나눈다.Level 1내에서는 서로가 겹치는 일이 없기 때문에, 같은 Level 끼리의 Compaction은 진행하지 않는다.Level n+1에서도Level n에서 선택한 범위와 겹치는 모든SSTable을 한번에 Compaction 한뒤 적절한 크기로 나눔으로써,Level n+1내에서 값이 겹치지 않는 상태로 유지한다.
전체 구조
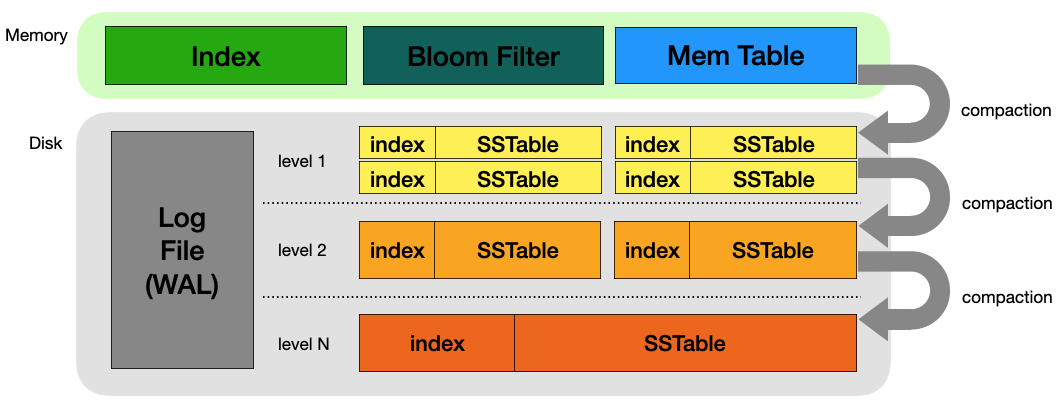 LSM tree의 전체 구조, 출처: NoSQL 데이터베이스가 빠른 이유 | LSM Tree 완전정복 | DB 의 데이터 저장 방법
LSM tree의 전체 구조, 출처: NoSQL 데이터베이스가 빠른 이유 | LSM Tree 완전정복 | DB 의 데이터 저장 방법
LSM tree의 전체 구조를 본다면 이렇게 됩니다.
- 메모리(Memory):
MemTable과Index,Bloom Filter가 있습니다. - 디스크(Disk): 여러 레벨의
SSTable이 있으며, 각 레벨 별로SSTable은 여러개 존재할 수 있습니다.
LSM tree? LSM Tree!!!
B+tree는 DB를 공부할 때 항상 RDB를 기준으로 공부했기 때문에 종종 들었지만, LSM Tree라는 단어를 처음 들었을 때 너무 생소했다. 그래도 이 글을 정리하며 LSM tree기반의 DB가 있다는 것을 알게되었고, 만약 내가 DB를 골라서 개발할 수 있다면, 애플리케이션이나 서비스의 특성에 따라 다른 DB를 선택해야겠구나 라는 생각을 가지게 됐다. 그 일부로 일단 B+tree와 LSM tree 둘 중에 하나는 선택할 수 있으니…
No sql DB는 생각보다 다양하니까 각 DB의 구조나 동작 방식에 대해 더 관심을 가져서, 서비스마다 좀 더 적절한 DB를 선택할 수 있는 능력을 길러야겠다.