Java Standard - java lang 패키지와 유용한 클래스
...
java.lang 패키지
java.lang패키지에는 자바 프로그래밍에 가장 기본이 되는 패키지를 포함하고 있고, 그렇기에 import문 없이도 사용 가능
Object 클래스
모든 클래스의 최고 조상, Object클래스의 멤버들은 모든 클래스에서 바로 사용 가능
equals(Object obj)
- 매개변수로 객체의 참조변수를 받아 비교 후 결과를 boolean값으로 리턴
- 두 객체의 비교를 참조변수 값으로 비교
참조변수 = 메모리의 주소값! 그렇기 때문에 객체가 다르면 같은 값이더라도, 각 객체가 저장되어있는 주소 값이 다르기 때문에 결과가
fasle로 나옴 동일한 객체를 바라보고있는 참조변수들을 비교하는 상황이라면true의 결과값을 얻음
String이나 Date, File등 여러 클래스는 equals를 오버라이딩해서 참조변수(주소값)이 아닌 저장된 값을 비교하도록 되어있음
hashCode()
- 해싱기법에 사용되는 해시함수를 구현한 것
- 호출시 객체의 주소값으로 해시코드를 만들어 반환함
해싱기법? 해시함수란? 해싱기법: 데이터 관리기법 중의 하나로 다량의 데이터를 저장하고 검색하는데 유용 해시함수: 찾고자하는 값을 입력하면, 그 값이 저장된 위치를 알려주는 해시코드(hash code)를 반환
해시코드의 중복 해시코드가 같은 두 객체가 존재 하는 것이 가능 hashCode(): 객체의 주소값을 기반으로 해시코드를 만들어 반환 32bit JVM: 서로 다른 두 객체는 결코 같은 해시코드를 가질 수 없음 64bit JVM: 8byte주소값으로 4byte해시코드를 만드는 것이라 중복이 될 수 있음
equals()를 오버라이드 시, hashCode도 같이 재정의 해야한다. equals()의 결과가 true 인 두 객체의 해시코드는 반드시 같아야한다는 자바의 규칙 hash 값을 사용하는 Collection Framework(HashSet, HashMap, HashTable)을 사용할 때 문제가 발생
이 순서로 객체가 같은지 논리적으로 비교하기 때문
- System.identityHashCode(Object x)
- 항상 모든 객체에 대해 항상 다른 해시코드값을 반환할 것을 보장 hashCode()는 각 클래스에서 오버라이딩 해서 사용하지만, 이건 그렇게 하기전의 원본 hashCode()메서드와 비슷하다고 생각하면됨
toString()
- 인스턴스 변수에 저장된 값들을 문자열로 표현, 인스턴스의 정보를 문자열로 제공
- 호출시 클래스이름에 16진수의 해시코드를 얻게 됨
- 각 클래스에서 클래스에 대한 정보 또는 인스턴스 변수들의 값을 문자열로 변환하도록 오버라이딩 하는 것이 보통
clone()
- 자신을 복제하여 새로운 인스턴스를 생성하는 일
- 목적: 원래의 인스턴스를 보존하기 위해서
- 특징
- 얕은 복사가 이루어짐
얕은 복사 vs 깊은 복사
얕은 복사: 기본 값은 복사되지만, 참조하고 있는 내용은 복사되지 않고 객체를 공유함(같이 참조함) → 둘 중 하나만 값을 바꾸면 둘 다 적용 깊은복사: 기본 값도 복사하고,참조하고 있는 내용도 복사 한뒤 복사한 내용을 참조함 → 둘 중 하나만 값을 바꾸면 그 값만 적용
- Cloneable인터페이스를 구현한 클래스(=복제를 허용)만
clone()을 통한 복제가 가능함
- 공변반환 타입
- 부모메서드의 반환 타입을 자식클래스로 변경을 허용하는 것
- ex) 상속 관계에 있는 클래스, 메서드의 리턴타입을 부모 → 자식 변경! Object 클래스에 정의된 내용: Object clone(){,,,} Child 클래스에서 오버라이드 한 내용 Child clone(){,,,}
getClass()
- 자신이 속한 클래스의 Class 객체를 반환
Class 객체란? 이름이 Class인 객체, 클래스의 모든 정보를 담고있고, 클래스당 1개만 존재함 class파일이 클래스 로더에 의해 메모리에 올라갈 때 자동적으로 생성됨 클래스 파일을 읽어서 사용하기 편한 상태로 저장해 놓은 것
클래스 로더란? 실행 시에 필요한 클래스를 동적으로 메모리에 로드하는 역할 로드 하는 방법
- 기존에 생성된 생성된 클래스 객체가 메모리에 있는지 확인
- 있으면, 객체의 참조를 반환
- 없으면, 클래스 패스(CLASS PATH)에 지정된 경로를 따라 클래스 파일을 찾음
- 찾으면, 해당 파일을 읽어 Class 파일로 변환
- 못찾으면, ClassNotFoundException이 발생
- Class객체를 얻는 방법
- 생성된 객체로부터 얻기:
new Object.getClass(); - 클래스 리터럴로부터 얻기:
Object.class; - 클래스 이름으로부터 얻기:
Class.forName(”Object”);forName()은 메모리에 올릴떄 주로 사용됨
- 생성된 객체로부터 얻기:
- Class객체 활용: 클래스의 모든 정보를 얻을 수 있어 보다 동적인 코드를 작성할 수 있음(리플렉션 API)
String 클래스
변경 불가능한 클래스
- String은 클래스 앞에
final이 붙어있으으로 다른 클래스의 조상이 될 수 없음 String인스턴스가 가지고 있는 값은 읽어 올 수만 있고, 변경은 불가능
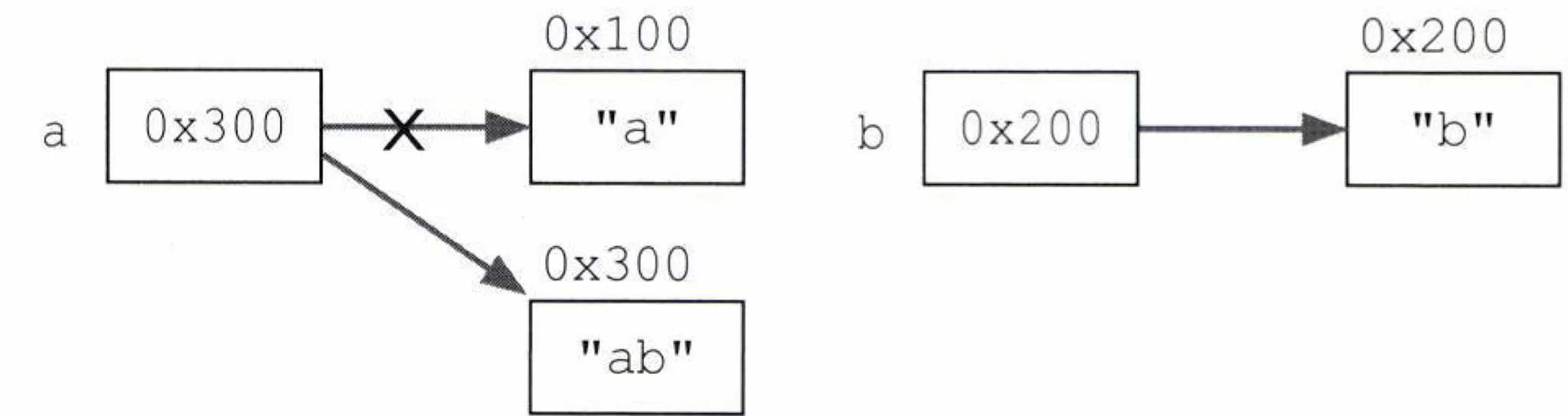
- 변경이 필요한 경우, 변경을 하는 것이 아니라 새로운 문자열을 만들고 해당 문자열 인스턴스를 만든 뒤 해당 인스턴스를 참조하게 되는 것
문자열 비교
- 문자열을 만드는 방법
- 문자열 리터럴을 지정하는 방법:
String str1 = “text“;→이미 존재하는 것이 있으면 재사용 - 생성자를 이용하는 방법:
String str2 = new String(”text”);→new연산자에 의해 메모리 할당이 이루어 지기 때문에 항상 새로운 인스턴스 생성
- 문자열 리터럴을 지정하는 방법:
equals()와 등가비교연산자==→ 결과가 다름equals(): String에서는 오버라이딩 되어 값을 비교하기 때문에 str1과 str2가 같음- 등가비교연산자
==: String의 인스턴스의 주소를 비교하기 때문에 str1과 str2가 다름
동등 비교와
문자열 리터럴
- 자바 소스파일에 포함된 모든 문자열 리터럴은 컴파일 시 클래스 파일에 저장됨
- 같은 내용의 문자열은 한번만 저장됨
- 문자열 리터럴도 String인스턴스
문자열도 String의 인스턴스로 취급되기 때문에
“”.equals(””)형식이 가능!!
- String인스턴스는 값이 변경될 수 없으니 하나만 생성해서 공유하면 되기 때문
- 클래스 파일에는 소스파일에 포함된 모든 리터럴 목록이 존재 → 클래스 로더에 의해 메모리에 올라갈 때 JVM내에 있는 “상수 저장소”에 등록
상수 저장소의 관리 방법 A 클래스 파일에 “text”라는 String인스턴스가 있어서 이미 저장된 상태에서, B 클래스 파일에도 똑같이 “text”라는 String인스턴스가 로드되면 저장을 하지 않나?!
빈 문자열
- String은 빈 문자열이 존재 할 수 있고, String은 빈 문자열로 초기화를 함
- char는 빈 값 안됨! char[0]이 가능한 것이지, char = ’’가 가능한 것이 아님!
java가 배열의 길이를 따로 저장하는 이유(추측) C언어는 배열의 끝에
널문자열을 붙임으로써, 문자열의 끝을 알리는데 java는 넣지 않는 대신 배열의 길이를 전부 관리!해서 끝을 알 수 있도록 함! → 근데 왜 C언어는 문자열에서만 마지막에 널을 붙일까? 다른 배열에서는 끝을 어떻게 알까?,, 다른 int 배열이나 이런데서 끝을 아는 방법을 char[]에서도 사용하면 되지 않나?!
String 클래스의 생성자와 메서드
- 생성자
- String을 받는 생성자
- char[]을 받는 생성자
- StringBuffer를 받는 생성자
- 메서드
- 형변환
String valueOf(): 기본 타입 → String 타입으로 형변환
- 찾기
char charAt(int index): 지정된 위치(index)에 있는 문자를 returnint indexOf(int ch): 문자(ch)가 문자열에 존재하는지 - return 있으면 위치 index, 없으면 음수int indexOf(int ch, int pos): 문자(ch)가 문자열에 존재하는지, 위치(pos)부터 검색 - return 있으면 위치 index, 없으면 음수int indexOf(String str): 문자열(str)이 문자열에 존재하는지 - return 있으면 위치 index, 없으면 음수int lastIndexOf(int ch): 문자(ch)가 문자열에 존재하는지, 뒤에서 부터 - return 있으면 위치 index, 없으면 음수int lastIndexOf(String str): 문자열(str)이 문자열에 존재하는지, 뒤에서 부터 - return 있으면 위치 index, 없으면 음수
- 비교
boolean contains(String str): 문자열(str)이 포함되어있는지 여부 returnboolean endsWith(String suffix): 문자열(suffix)로 끝나는지 여부 returnboolean startsWith(String prefix): 문자열(prefix)로 시작하는지 여부 returnint compareTo(String str): 문자열(str)과 사전순서로 비교 - return 사전순이면 음수, 이후면 양수boolean equals(Object obj): 문자열과(obj)와 String인스턴스의 값 비교 returnboolean equalsIgnoreCase(Object obj): 문자열과(obj)와 String인스턴스의 대소문자 구별없이 값 비교 return
- 변경
String replace(CharSequence old, CharSequence new): 문자열 중 문자열(old)를 새로운 문자열(new)로 바꿈String replaceAll(String regex, String new): 문자열 중 문자열(regex)과 일치하는 문자열을 새로운 문자열(new)로 바꿈String replaceFirst(String regex, String new): 문자열 중 문자열(regex)과 일치하는 문자열을 첫번째 것만 새로운 문자열(new)로 바꿈
- 자르기
String[] split(String regex): 문자열을 분리자(regex)로 자름String[] split(String regex, int limit): 문자열을 분리자(regex)로 지정된 수(limit)만큼 자름String substring(int begin): 시작위치(begin)부터 문자열을 자름String substring(int begin, int end): 시작위치(begin)부터 끝위치(end)까지 문자열을 자름, 끝위치는 포함되지 않음
- 그 외
String concat(String str): 문자열(str)을 뒤에 덧붙인 문자열을 returnString intern(): 상수풀에 등록, 등록되어있으면 그 문자열의 주소값 returnint length(): 문자열의 길이 returnString toLowerCase(): 모든 문자열을 소문자로 변환String toUpperCase(): 모든 문자열을 대문자로 변환String trim(): 양 끝의 공백을 제거
- 형변환
join()과 StringJoiner
join(): 여러 문자열 사이에 구분자를 넣어서 결합, split과 반대1 2 3 4 5
String[] strArr = {"aaa", "bbb", "ccc"}; String str = String.join("-"); //결과 aaa-bbb-ccc
java.util.StringJoiner: join과 비슷하지만, 구분자 뿐만 아니라 시작과 끝도 지정할 수 있음
1 2 3 4 5 6 7 8
StringJoiner sj = new StringJoiner("," , "[", "]"); String[] strArr = {"aaa", "bbb", "ccc"}; for(String a: strArr){ sj.add(s.toUpperCase()); } // 결과 [AAA,BBB,CCC]
유니코드의 보충문자
보충문자
유니코드는 원래 2byte, 16bit 문자체계, 이걸로 모자라서 20byte로 확장
이렇게 확장에 의해 추가된 문자들은 보충문자 라고 함
→ 보충문자는 하나의 문자를 char로 다루지 못하고 int로 다뤄야함
보충문자를 지원하는 메서드 구별법
- 매개변수가 int → 지원
- 매개변수가 char → 미지원
문자 인코딩
- JAVA는 UTF-16의 인코딩을 사용하지만, 문자열 리터럴의 인코딩은 OS의 인코딩을 사용
getBytes(String charsetName)을 이용하면 문자열의 인코딩을 다른 인코딩으로 변경 가능
String.format()
- 형식화된 문자열을 만들어내는 간단한 방법
- printf()와 사용법이 같음
기본값을 String으로 변환
숫자 + “” 보다는 valueOf() 가 성능이 더 좋음
String값을 기본값으로 변환
valueOf() 와 parse타입() 두가지가 있지만, valueOf()는 내부적으로 parse타입() 를 호출하는 것 뿐으로 차이가 없음
StringBuffer 클래스와 StringBuilder 클래스
StringBuffer 클래스의 특징
- 내부적으로 문자열 편집을 위한 버퍼(buffer)를 가지고 있음 → 문자열 수정이 가능한 이유
- String 클래스와 유사
- 문자열을 저장하기 위한 char형 배열의 참조변수를 인스턴스 변수로 선언
- StringBuffer인스턴스가 생성될 때 char형 배열이 생성되며, 인스턴스 변수가 참조
StringBuffer의 생성자
- 인스턴스를 생성할 때, 적절한 길이의 char형 배열(=buffer, 문자열 저장 및 편집)이 생성
- 길이를 여유롭게 지정하지 않아 부족하게 되면 내부적으로 길이를 증가시키는 작업을 진행
- 이때 배열의 길이는 변경될 수 없음으로 새로운 배열(이전보다 큰 배열) 생성 후 복사
StringBuffer의 변경
sb 생성
StrinbBuffer sb = new StringBuffer(”abc”);
문자열 123추가
sb.append(”123”);
append()는 문자열에 새로운 문자열이 추가되고, sb의 주소를 반환한다. 그렇기 때문에 sb.append(”123”).append(”456”)과 같이 연속적인 호출이 가능한 것!
StringBuffer의 비교
toString()을 통해 String인스턴스를 얻음- String인스턴스의
equals()로 값을 비교함
String은 equals메서드를 오버라이딩 했지만, StringBuffer는 오버라이딩 하지 않았기 때문
StringBuffer클래스의 생성자와 메서드
- 생성자
- 기본 생성자: 16문자를 담을 수 있는 인스턴스 생성
- String을 받는 생성자: 인스턴스 생성
- int를 받는 생성자: 버퍼크기 지정
- 메서드
- 추가
StringBuffer append(): 기본타입의 매개변수를 String으로 변환한 뒤, 뒤에 덧붙임StringBuffer insert(int pos): 기본타입의 매개변수를 String으로 변환한 뒤, 위치(pos)에 추가
- 삭제
StringBuffer delete(int start, int end): 시작위치(start)부터 끝위치(end)까지의 문자를 제거, 끝문자는 제외StringBuffer deleteAt(int index): 위치(index)의 문자를 제거
- 그 외
int capacity(): 인스턴스의 버퍼크기를 알려줌, 버퍼크기와 문자열 길이는 다름StringBuffer reverse(): 문자열의 순서를 거꾸로 나열void Length(int newLength): 문자열의 길이를 변환, 늘리는 경우 나머지를 널로 채움
- 추가
StringBuilder란?
- StringBuffer: 동기화 O → 멀티쓰레드에 안전하지만, 멀티쓰레드가 아닌경우 불필요한 성능저하
- StringBuilder: 동기화 X → StringBuffer에서 동기화만 제거한 같은 클래스
Math 클래스
- 기본적인 수학계산에 유용한 메서드로 구성
- 인스턴스 생성 불가능 → 생성자가 private, 인스턴스 멤버가 없고 전부 static
올림, 버림, 반올림
- 올림
ceil(): 실수를 올림해서 double로 결과를 돌려줌
- 버림
floor(): 실수를 버림해서 double로 결과를 돌려줌- 음수에서 버림을 하면 수가 더 낮아짐, ex) floor(-1.5) → -2
- 반올림
round(): 소수점 첫째자리에서 반올림 해서 long로 결과를 돌려줌rint(): 소수점 첫째자리에서 반올림해서 double로 결과를 돌려줌- 두 정수 가운데 값을 반올림 할 때는 짝수로 반환함
올림, 버림, 반올림 등 계산을 특정 소수점에서 하고 싶으면 10의 n제곱과 같이 계산해야함
ex) 10.245854 를 소수 4번째 자리에서 반올림 하고싶다면
10.245854에 1000을 곱한다 10.245854 * 1000 = 10245.85410245.854에서 반올림을 한다. round(10245.854) → 1024610246 에 1000.0을 나눈다. 10246 / 1000.0 = 10.246 → 1000.0으로 나누는 이유 10246 / 1000 = 10
예외를 발생시키는 메서드
- 메서드이름에
Exact가 포함된 메서드 - 정수형간의 연산에서 발생할 수 있는 오버플로우를 감지하기 위한 것
- 오버플로우의 발생여부에 대해 알려주지는 않지만, 발생하면 예외를 발생시킴
삼각함수와 지수, 로그
sqrt(): 제곱근pow(): n제곱
StrictMath클래스
어떤 OS에서 실행이 되어도 항상 같은 결과를 얻도록 작성된 Math 클래스
Math클래스 Math클래스는 최대한의 성능을 얻기 위해 JVM이 설치된 OS의 메서드를 호출에서 사용함 즉 OS에 의존적인 계산을 하는 것 그렇기 때문에 부동소수점 계산의 경우, 반올림의 처리방법 설정이 OS마다 다를 수 있기 때문에 자바로 작성된 코드라도 결과가 다를 수 있음
Math클래스의 메서드
abs(): 절대값max(): 큰 값min(): 작은 값random(): 랜덤 값(0~1.0, 1.0은 포함 안됨)
래퍼(Wrapper) 클래스
- 의미: 기본형 값을 객체로 다룰 수 있는 클래스
- 특징
- 생성자의 매개변수로 문자열이나 각 자료형의 값을 받음
- 객체 생성시, 인자로 주어진 값을 각 자료형에 알맞은 값으로 내부적으로 저장하고 있음
equals()가 모두 오버라이딩 되어있어 값을 비교함toString()도 오버라이딩 되어있어 값을 문자열로 변환함
Number 클래스
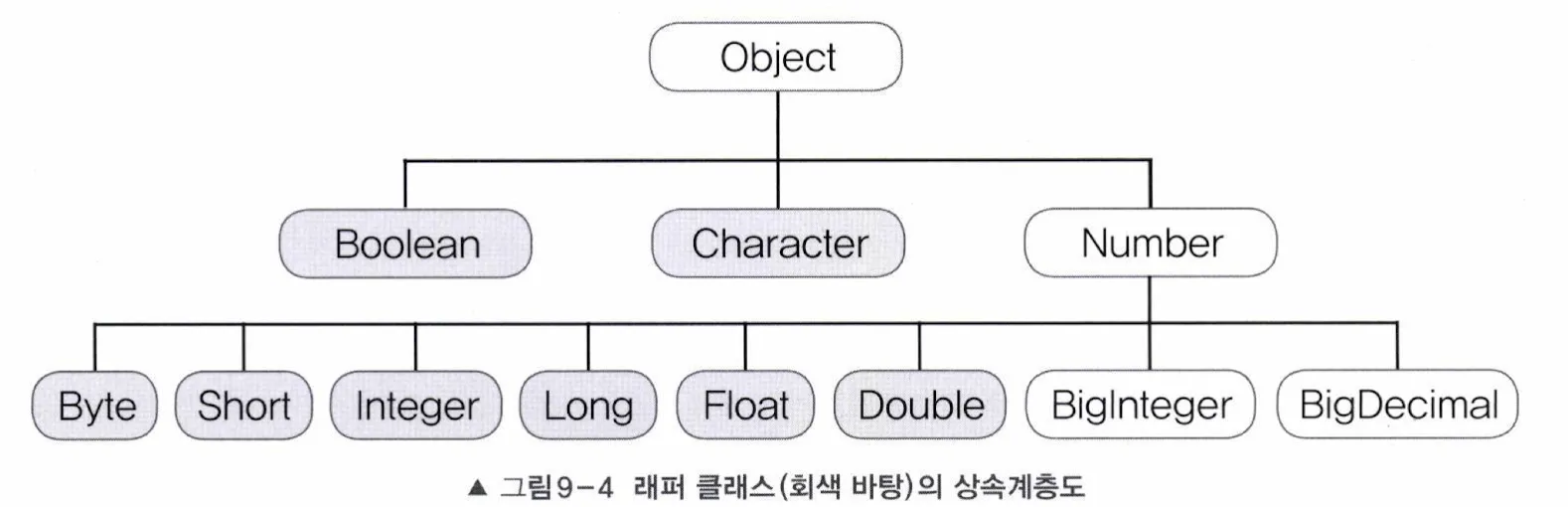
- 추상클래스로 내부적으로 숫자를 멤버변수로 갖는 래퍼 클래스의 조상
문자열을 숫자로 변환하기
Integer.parseInt(): 리턴이 기본타입Integer.valueOf(): 리턴이 래퍼타입, 조금 더 느림
오토박싱과 언박싱
- 기본형 → 래퍼 클래스 : 오토박싱
- 래퍼 클래스 → 기본형 : 언박싱
참조형과 기본형의 연산이 안되어 타입을 맞추고 연산을 해야하지만,
컴파일러가 자동으로 변환하는 코드를 넣어주기 때문에 연산이 가능함 (이전에는 코드로 작성해야했음, 자바의 규칙이 바뀐 것이 아님)
유용한 클래스
java.util.Objects 클래스
특징
- Object클래스의 보조 클래스
- 모든 메서드가 static
- 객체의 비교나 널체크에 유용
메서드
isNull(): 널체크requiredNonNull(): 널이 아니여야하는 경우에 사용, 널이면NullPointerException발생compare(): 대소비교(같으면 0, 크면 양수, 작으면 음수), 비교 기준은 ComparatordeepEquals(): 다차원 배열의 비교도 가능equals(): 둘 다 null 이여도 참hashCode(): 내부적으로 널 검사를 한 후에hashCode()호출, 널이면 0
java.util.Random 클래스
특징
- Math의 random()도 사실 내부적으로는 Random인스턴스 사용
- Random의 seed: 난수를 만드는 공식에 사용되는 값
같은 seed를 넣으면 항상 같은 난수를 순서대로 얻음
실행시간, 시스템 등에 관계없이 항상 같은 값을 같은 순서로 반환할 것을 보장
Math클래스는 seed를
System.currentTimeMills()로 입력해 매번 달라짐
→ Random클래스와 Math클래스의 차이
생성자와메서드
- 생성자
Random():System.currentTimeMills()를 seed로 이용해 인스턴스 생성Random(long seed): 매개변수를 seed로 이용해 인스턴스 생성
- 메서드
- 난수 반환
boolean nextBoolean(): boolean타입의 난수를 반환double nextDouble(): double타입의 난수를 반환 (0.0 ≤ x ≤ 1.0)double nextGaussian(): double타입의 난수를 반환, 가우시안 분포에 따른 난수float nextFloat(): float타입의 난수를 반환 (0.0 < x < 1.0)int nextInt(): int타입의 난수를 반환 (int의 범위)int nextInt(int n): int타입의 난수를 반환 (0~n, n은 미포함)long nextLong(): long타입의 난수를 반환 (long의 범위)
- 기타
void nextBytes(byte[] bytes): byte배열에 난수를 채워서 반환void setSeed(long seed): 종자값을 주어진 값으로 변경
- 난수 반환
정규식(Regular Expression) - java.util.regex 패키지
정규식이란?
텍스트 데이터 중에서 원하는 조건(패턴)과 일치하는 문자열을 찾아내기 위해 사용하는 것으로 미리 정의된 기호화 문자를 이용해서 작성한 문자열을 말함
관련 클래스
- Pattern 클래스: 정규식을 정의 하는데 사용
- Matcher 클래스: 정규식을 데이터와 비교하는 역할을 함
정규식 사용 과정
Pattern의 인스턴스 얻기
Pattern pattern = Pattern.compile("정규식")Matcher의 인스턴스 얻기
Matcher matcher = p.matcher(검사할 string)Matcher인스턴스의 메서드를 이용해 정규식에 부합하는지 확인
if(matcher.matches())
java.util.Scanner 클래스
다양한 입력소스로부터 데이터를 읽을 목적의 클래스
특징
- 정규식을 이용한 라인단위의 검색을 지원
- 구분자에도 정규식을 사용할 수 있어 복잡한 형태의 구분자도 처리 가능
- 다양한 생성자를 통해 다양한 입력소스로부터 데이터를 읽어올 수 있음
java.util.StringTokenizer 클래스
긴 문자열을 지정된 구분자를 기준으로 토큰이라는 여러 개의 문자열로 잘라내는 데 사용됨
특징
- 구분자로 단 하나의 문자 밖에 사용 못함 → 복잡한 형태의 구분자는 처리 못함
- 구분자에 “^&)”를 넣어도 “^” “&” “” “)” 이렇게 각각을 의미 하는 것임
- split()과의 비교
- String
split()은 빈 문자열을 토큰으로 인식함- 데이터를 토큰으로 잘라낸 결과를 배열에 담아서 반환
- StringTokenizer
- 빈 문자열은 토큰으로 인식하지 않음
- 토큰으로 바로바로 잘라서 반환 → split()보다 성능이 좋음 (미미하지만,,)
- String
생성자와 메서드
- 생성자
StringTokenizer(String str, String delim): 문자열(str)을 구분자(delim)로 나누는 StringTokenizer 생성, 구분자는 토큰으로 간주되지 않음StringTokenizer(String str, String delim, boolean returnDelims): 문자열(str)을 구분자(delim)로 나누는 StringTokenizer 생성, 구분자는 토큰으로 간주되는지 여부(returnDelims)
- 메서드
int countTokens(): 전체 토큰의 수를 반환boolean hasMoreTokens(): 토큰이 남아있는지 알려줌String nextToken(): 다음 토큰을 반환
java.math.BigInteger 클래스
long보다 더 큰 값의 정수형을 다룰 때 사용함
String을 사용하는 것과의 차이는? 비트 연산자를 사용하는 메서드 등의 차이가 있어 BigInteger클래스가 더 유용할 것 같다.
특징
- 내부적으로 int배열을 사용해 값을 저장함 → long 보다는 성능이 떨어짐
- 내부적으로 저장되는 int 배열이 불변임
- 2의 보수: 정수형이 형태가 2의 보수로 표현되듯 BigInteger클래스도 형태로 표현됨
생성
- 문자열로 생성 → 일반적, 나머지는 값의 범위가 있기 때문에
- n진수로 생성
- long타입의 리터럴로 생성
타입 변환
- Number로부터 상속받은 기본형으로 변환하는 메서드를 가지고 있음
- 끝에 Exact가 붙은 것은 변환 결과가 타입범위에 속하지 않으면
ArithmeticException을 발생
연산
- 기본적인 연산을 수행하는 메서드가 정의되어 있음
- 성능 향상을 위해 비트단위의 연산을 수행하는 메서드가 많이 정의 되어있음
- BigInteger는 불변이라 새로운 인스턴스를 생성해 결과를 반환함
java.math.BigDecimal 클래스
오차가 없는 실수를 다룰 때 사용함
특징
기존의 실수는 10진 실수를 2진 실수로 변환 = 오차를 피할 수 없음
→ 2진 정수로 변환해서 다룸 ⇒ 오차가 없음
- 실수를 정수와 10의 제곱의 곱으로 표현
- 제곱의 수 범위: 0~
Integer.MAX_VALUE사이 - 내부적으로 저장되는 값이 불변임
생성
- 문자열로 생성 → 일반적, 숫자형 리터럴은 한계가 있기 때문
- double타입의 리터럴로 생성
- int, long타입의 리터럴로 생성
- static
valueOf()로 double, int 타입의 매개변수를 이용해 생성 → 오차가 발생할 수 있음
타입변환
- 지수형태의 리터럴을 사용해 생성시,
toPlainString()과toString()의 결과가 다를 수 있음 - 끝에 Exact가 붙은 것은 변환 결과가 타입범위에 속하지 않으면
ArithmeticException발생
연산
- BigDecimal는 불변이라 새로운 인스턴스를 생성해 결과를 반환함
- 나눗셈을 처리하는 메서드는 다양한 버전이 존재함 → 반올림에 관한처리 등으로 인해
- 아무리 오차없이 처리하는 BigDecimal이라도, 나눗셈에서 발생하는 오차는 어쩔수 없음
divide()결과가 무한소수인경우, 반올림 모드 미지정시ArithmeticException발생ex) 1.0/3.0 과같은 나눗셈